Launching CPC3
· 3 min read

- 3rd Clarity Prediction Challenge (CPC-3)
- Launch: March 17th; Submission: July 31st, 2025
- Workshop: 22nd August 2025, an INTERSPEECH satellite workshop
- https://claritychallenge.org/
Dear colleague,
It gives us great pleasure to announce the launch of the 3rd Clarity Speech Separation and Recognition Challenge (CPC3).
The Challenge
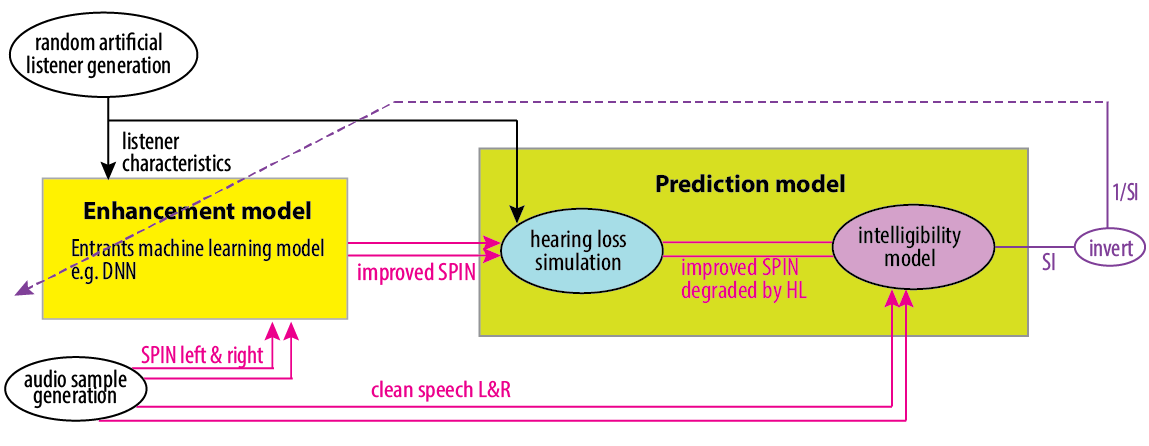
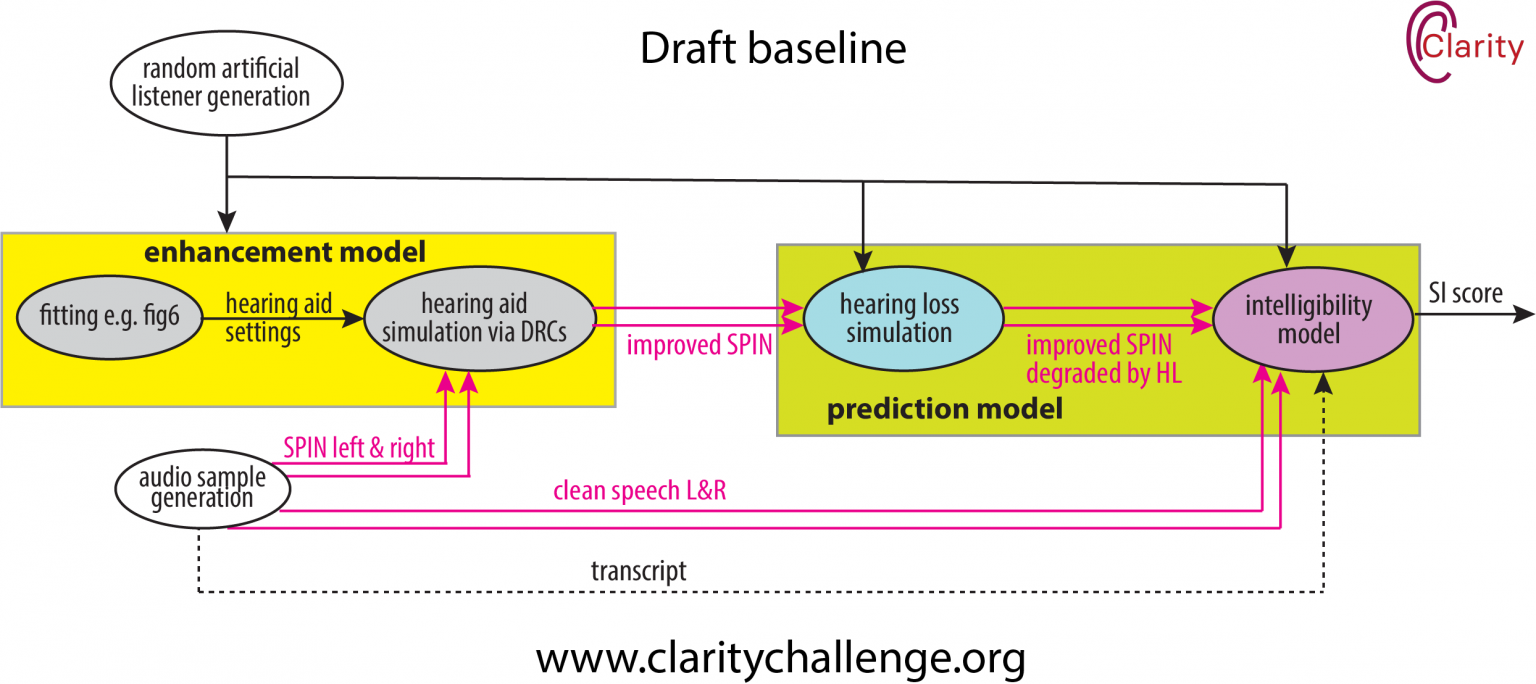
To improve hearing enhancement technologies, such as hearing aids and hearable devices, we need reliable methods for automatically assessing the speech intelligibility of audio signals.
In recent years, we have organised the CPC1 and CPC2 Challenges to promote the development of such prediction systems. We are now launching the third round of this challenge, building on previous efforts by incorporating a more extensive and diverse set of listener data for training and evaluation.
What will be provided
- Hearing aid outputs: Audio produced by various simulated hearing aids while processing speech in noisy environments.
- Clean speech reference signals
- Listening Test Results: This includes transcripts and intelligibility scores from tests in which hearing-impaired listeners were asked to repeat what they heard.
- Listener Characteristics: Information regarding the severity of hearing impairment for each listener.
- Software Tools: Tools include a baseline system based on HASPI scores.