Improving hearing aid processing using DNNs blog. A suggested approach to overcome the non-differentiable loss function.
The aim of our Enhancement Challenge is to get people producing new algorithms for processing speech signals through hearing aids. We expect most entries to replace the classic hearing aid processing of Dynamic Range Compressors (DRCs) with deep neural networks (DNN) (although all approaches are welcome!). The first round of the challenge is going to be all about improving speech intelligibility.
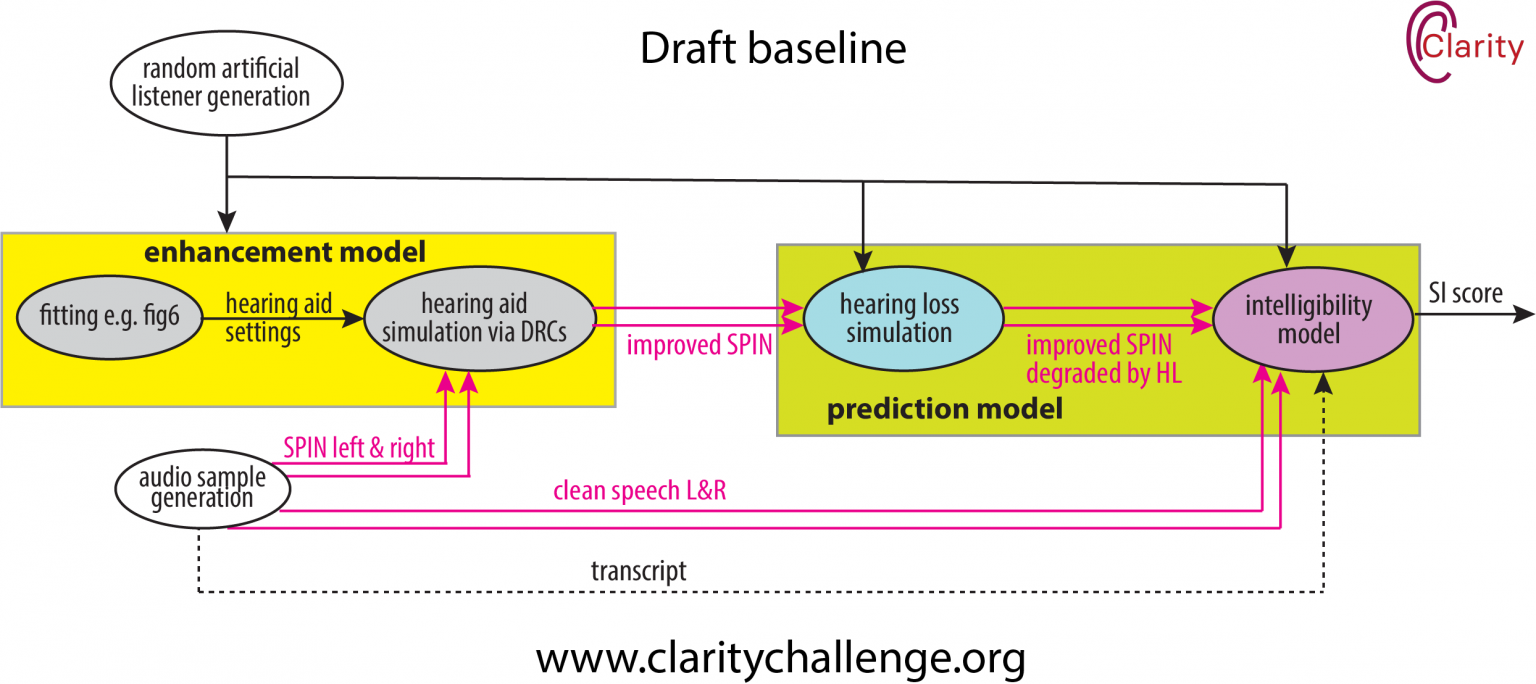
Setting up a DNN structure and training regime for the task is not as straightforward as it might first appear. Figure 1 shows an example of a naive training regime. An audio example of Speech in Noise (SPIN) is randomly created (audio sample generation, bottom left), and a listener is randomly selected with particular hearing loss characteristics (random artificial listener generation, top left). The DNN Enhancement model (represented by the bright yellow box) then produces improved speech in noise. (Audio signals in pink are two-channel, left and right because this is for binaural hearing aids.)
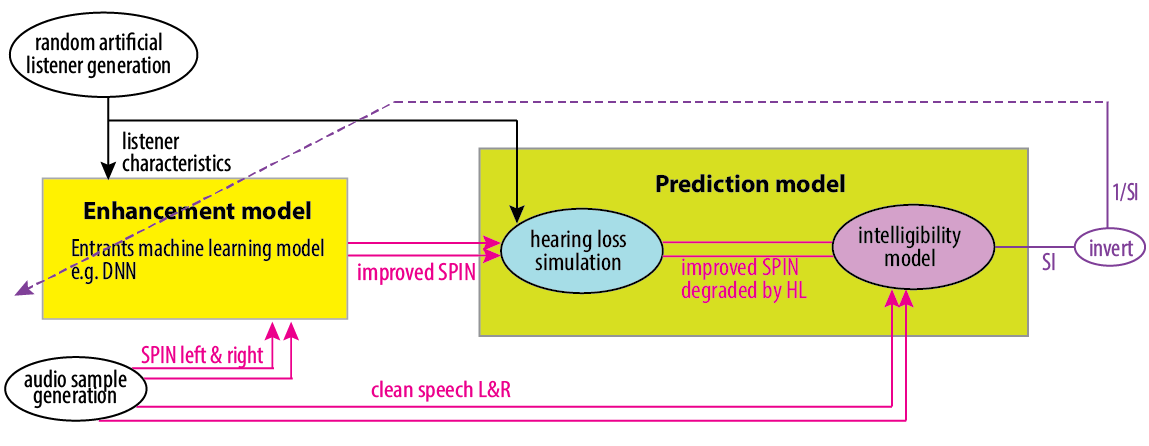
Figure 1
Next the improved speech in noise is passed to the Prediction Model in the lime green box, and this gives an estimation of the Speech Intelligibility (SI). Our baseline system will include algorithms for this. We’ve already blogged about the Hearing Loss Simulation. Our current thinking is that the intelligibility model will be using a binaural form of the Short-Time Objective Intelligibility Index (STOI) [1]. The dashed line going back to the enhancement model shows that the DNN will be updated based on the reciprocal of the Speech Intelligibility (SI) score. By minimising (1/SI), the enhancement model will be maximising intelligibility.