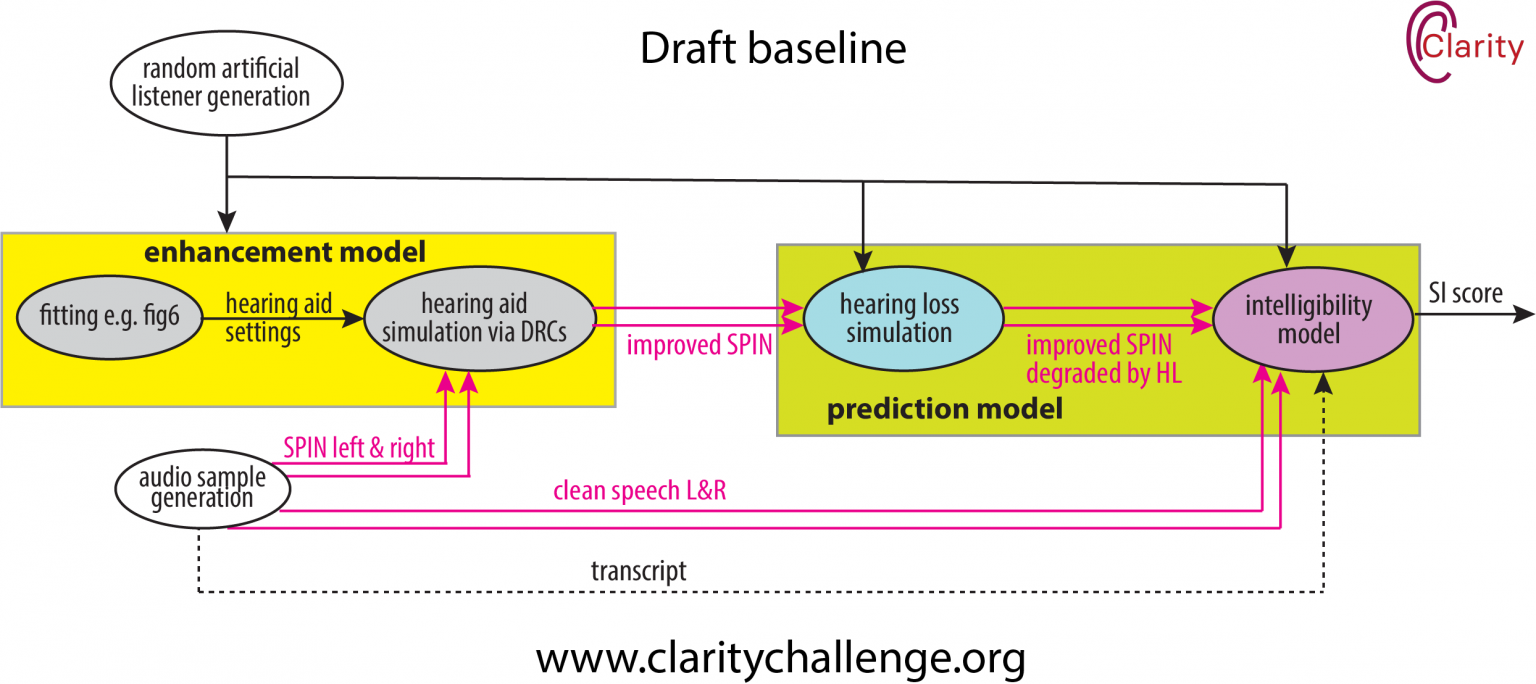
Release of CEC2 baseline

We are pleased to announce the release of the 2nd Clarity Enhancement Challenge (CEC2) baseline system code.
The baseline code has been released in the latest commit to the Clarity GitHub repository.
The baseline system perform NAL-R amplification according to the audiogram of the target listener, followed by a simple gain control and output of the signals to 16-bit stereo wav format. The system has been kept deliberately simple with no microphone array processing or attempt at noise cancellation.
HASPI scores for the dev set have been measured. The scores are as follows.
| System | HASPI |
|---|---|
| Unprocessed | 0.1615 |
| NAL-R baseline | 0.2493 |
See here for further details.
If you have any problems using the baseline code please do not hesitate to contact us at claritychallengecontact@gmail.com, or post questions on the Google group.