Task 3 Data
The Task 3 data consists of simulated hearing aid inputs that have been constructed using a set of real high-order ambisonic noise backgrounds and high-order ambisonic impulse responses that were recorded for the challenge. Target materials were added to the backgrounds in a similar manner to that used in Task 1, i.e. with the target speaker onsetting shortly after the scene starts and with a listener head rotation. Data has been split into two sets: 6,000 scenes for training and a 2,500 scene development set. A further 1,500 scenes were recorded and have been set aside for evaluation.
The data is organised into the following directories, and can be obtained from the download page.
clarity_CEC3_data
|── manifest
|── task1
|── task2
└── task3
└── clarity_data
|── metadata - metadata describing the scene construction
|── train
| |── scenes - audio and headtracking data for training scenes
| |── backgrounds - complete set of background recordings available for training
| └── targets - complete set of target signals available for training
└── dev
|── scenes
|── backgrounds
|── targets
└── speaker_adapt - speaker adaptation utterances (see below)
The sections below describe the recording setup, the format of the audio and headtracking data, and the metadata provided for each scene.
Recording setup
Ambisonic recordings were made using the em64 (Eigenmike), from mh acoustics. This 64-channel spherical microphone was used to record directly in 6th-order ambisonic format. Background sound fields were recorded at a railway station, beside roads and during a specially-orchestrated social event. Target speech is added to these background scenes using ambisonic impulse responses. The impulse responses were recorded using the tone-sweep method (Farina, 2007) using a 20-second logarithmic tone sweep from 65 to 20,000 Hz.
A measurement rig was developed that included a portable power supply with the Eigenmike and a laptop for recording, and a stereo amplifier (Cambridge A1) and a stand-mounted loudspeaker (Mission M30i) for recording the tone sweeps. The microphone and loudspeaker was positioned at approximate human head level (~1.5 m). In some recordings the microphone was on a separate stand at a similar height.

The roadside recordings were obtained from a variety of different recording positions next to busy roads in central Cardiff over six different recording sessions. The railway recordings were all made on platforms at Newport station on two separate days. For the outdoor recordings it proved impractical to record impulse responses against these noisy backgrounds, so an independent set of outdoor impulses were recorded from quieter locations (e,g., see above). Consequently, there is no relationship between the acoustic reflection patterns in the outdoor recordings and the outdoor impulse responses.
The majority of the outdoor recordings were made using the microphone windshield fitted (see figure above). The indoor recordings were made in a common room at Cardiff University (6m × 10m) with just over 20 people in the room (the numbers fluctuated) over a single 2-hour recording session. These recordings were made from 6 locations in the room and corresponding impulse responses for the same locations were recorded while the room was empty. In this case, therefore, the impulse responses carry the same reflection pattern as the field recordings. Participants were moved from one end of the room to the other after the first hour, so that they would always be in the same part of the room as the microphone.
The hearing aid signal simulation
The hearing aid input signals are simulated using similar processes to those were previously used in the 2nd Clarity Enhancement Challenge and used for Task 1. The only difference is that we use the background recordings rather than add point noise sources to the scene. Key details are summarised below.
Head rotation
As with Task 1, the listener make a small head rotation during the scene.
- Start of rotation is between -0.635 s to 0.865s (rectangular probability) relative to the start of the target utterances.
- The rotation lasts for 200 ms (standard deviation =10 ms)
- The start angle and end angle are recorded the the scene description metadata and the rotation typically between 20 and 30 degrees.
Signal-to-noise ratio (SNR)
The SNR of the mixtures are engineered to achieve a suitable range of speech intelligibility values. A desired signal-to-noise ratio, SNR (dB), is chosen at random. This is generated with a uniform probability distribution between limits determined by pilot listening tests. The better ear SNR (BE_SNR) models the better ear effect in binaural listening. It is calculated for the reference channel (channel 1, which corresponds to the front microphone of the hearing aid). This value is used to scale all interferer channels. The procedure is described below.
For the reference channel,
- The segment of the summed interferers that overlaps with the target (without padding), , and the target (without padding), , are extracted
- Speech-weighted SNRs are calculated for each ear, SNR and SNR:
- Signals and are separately convolved with a speech-weighting filter, h (specified below).
- The rms is calculated for each convolved signal.
- SNR and SNR are calculated as the ratio of these rms values.
- The BE_SNR is selected as the maximum of the two SNRs: BE_SNR = max(SNR and SNR).
Then per channel,
- The summed interferer signal, i, is scaled by the BE_SNR
- Finally, i is scaled as follows:
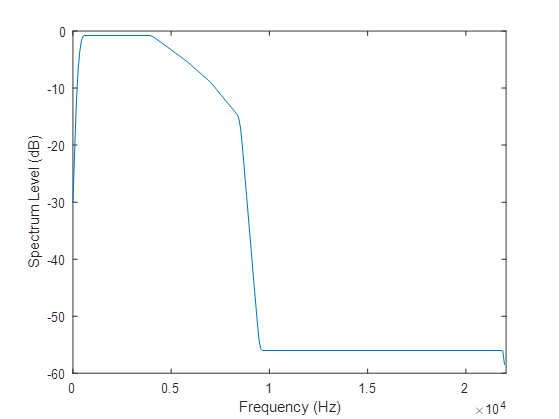
The speech-weighting filter is an FIR designed using the host window method [2, 3]. The frequency response is shown in Figure 2. The specification is:
- Frequency (Hz) =
[0, 150, 250, 350, 450, 4000, 4800, 5800, 7000, 8500, 9500, 22050] - Magnitude of transfer function at each frequency =
[0.0001, 0.0103, 0.0261, 0.0419, 0.0577, 0.0577, 0.046, 0.0343, 0.0226, 0.0110, 0.0001, 0.0001]
Signal generation
The scene renderer processing is shown in more detail in Figure 2 and is described below:
- It takes the ambisonics room impulse responses (RIR); the target and interferer audio; and the scene definition metadata as the input.
- It generates the HOA (High Order Ambisonic) target signals by convolution with the specified HOA impulse response.
- This is added the the HOA background at the the specified SNR.
- Next, it applies the head rotations by rotating the combined target and background HOA signals.
- Finally, we apply the Head Related Room Impulse Responses (HRIR) to create the binaural signals at the hearing aid microphones.
Audio Data format
Audio for the scenes
All the scene audio data is provided in 16-bit PCM format at a sample rate of 48000 kHz. File names have been designed to be compatible with previous Clarity challenges. For each scene the following audio files are provided:
- <SCENE_ID>_mix_CH1.wav - the left and right stereo pair from the front microphone.
- <SCENE_ID>_mix_CH2.wav - the left and right stereo pair from the middle microphone.
- <SCENE_ID>_mix_CH3.wav - the left and right stereo pair from the back microphone.
- <SCENE_ID>_hr.wav - the head rotation signal
- <SCENE_ID>_reference.wav - the signal to be used as the reference for HASPI evaluation.
The reference signal is an anechoic version of the target that is to be used as the standard reference for HASPI evaluation. It has been generated by swapping the measured echoic ambisonic impulse response, for an anechoic equivalent. It will share the delay and rotation characteristics of the echoic reference. It uses the HRTFs of the front microphone pair.
The head rotation signal indicates the precise azimuthal angle of the head at each sample. It is stored as a floating point wav file with values between -1 and +1 where the range maps linearly from -180 degrees to +180 degrees. You are free to use this signal in your hearing aid algorithm, but if you do so we would also ask that you evaluate an equivalent version of the system that does not use it (i.e., an ablation study), so that the benefit of known head motion can be measured.
Background noise recordings
The 6th order B-format ambisonic background recordings have also been made available. These can be used to extend the training set. The files are stored in the backgrounds directory and are named as follows:
cec3_<LOCATION>_<SESSION>_<SAMPLE_INDEX>_hoa.wv
Where <LOCATION> is the location of the recording (e.g., 'station', 'road', 'party'), <SESSION> is the recording session ID, and <SAMPLE_INDEX> is the unique index for the background recording within the session.
They are stored in .wv format generated by applying wavpack to losslessy compress the original 49-channel ambisonic recordings. The original uncopressed wav files can be recovered by running the following command in the backgrounds directory:
wvunpack *.wv
If your system does not have wvunpack installed, you can download it from the wavpack website.
Speaker adaptation data
The scenes that you have been asked to enhance often contain speech signals as interferers. This means that the task of enhancing the target speaker is ambiguous unless you are told which of the speaker to use as target. In this task, we follow the approach used in CEC2 and provide a small set of clean target speaker example utterances. So, for each scene, the ID of the target speaker is provided in the metadata, and systems can then use the examples and select the target as the one that has the matching voice.
Note, these same utterances will be used in the final subjective listening tests, i.e. the listeners will be presented with the examples before listening to the processed signal and told that these are examples of the target speaker that they are meant to be listening to.
Metadata Formats
The following metadata files are provided
# The description of the scenes
- scenes.[train|dev].json - metadata for the training/dev scenes
- rooms.[train|dev].json - metadata for the training/dev 'rooms' (i.e., impulse responses)
# Listener information
- scenes_listeners.dev.json - the listeners/scene pairings to for the standard development set
- listeners.json - the audiograms of the listeners
# Materials used to make up the scenes
- background.json - a description of the background noise recordings
- target_speech_list.json - the list target utterances
We've aimed to be consistent with the formats used in CEC2 and other CEC3 tasks. The most important files are the scenes.json and rooms.json files and these are described below. The scenes files contain all the data that was necessary to define the audio samples, i.e. the background, target, head rotation, SNR, the target impulse response. The target impulse responses are stored in the`rooms.json' - although many were recorded outdoors, we are using the term 'room' to be consistent with Task 1 and Task 2.
The Scene Metadata
The scene metadata is stored in a JSON file as a list of dictionaries with one dictionary for each scene. There are 6000 scenes in the training set and 2500 in the development set. A further 1500 have been retained for the final evaluation.
[
{
"scene": "S00508", // The Scene ID (S00001 to S10000)
"room": "cec3_party_S13_03", // Specifies the 'room' (i.e., the impulse response) that was used for the target
"target": { // The target description
"name": "T001_FRD_00503", // The utterance ID which starts with the talker ID (T001 to T040)
"time_start": 77020, // The sample at which the target starts
"time_end": 176245, // The sample at which the target ends
},
"background": {
"time_start": 0, // The sample at which the background starts (always 0)
"time_end": 248105, // The sample at which the background ends (always the end of the scene)
"name": "cec3_party_S13_014_hoa.wav", // The background noise file used
"type": "party", // The type of background (can be 'party', 'road', 'station')
"offset": 132903 // // The offset of the background sample in the complete background audio file
},
"listener": {
"rotation": [ // Describes a rotation in the horizontal plane
{
"sample": 74252.5369, // The time (in samples) at which the rotation starts
"angle": 71.2240 // The initial angle in degrees
},
{
"sample": 82883.5369, // The time (in samples) at which the rotation starts
"angle": 97.4871 // The final angle degrees
}
],
"hrir_filename": [ // The HRIR used to simulate the hearing aid inputs
"BuK-ED", // The 'ear drum' HRIR
"BuK-BTE_fr", // The front microphone HRIR
"BuK-BTE_mid", // The middle microphone HRIR
"BuK-BTE_rear" // The rear microphone HRIR
]
}
"SNR": -1.1145819681656075, // The SNR of the target signal (-12 to 6 dB)
"duration": 220345, // The duration of the scene in samples
"dataset": "train" // Can be train, dev or eval
},
... // more scenes
]
The Room Metadata
The 'room' metadata is stored in a JSON file as a list of dictionaries, with one dictionary representing each room. The format is as follows:
[
{
"name": "cec3_party_S12_03", // The name of the IR (matches the audio file name)
"ir_location": "party_S12", // Location ('external' or 'party_Sxx')
"dimensions": "13.3m x 6m", // Dimension of room
"listener": { // Not important -- always at (0,0,1.6) with view vector (1,0,0)
"position": [
1.5,
2.5,
1.5
],
"view_vector": [
1.0,
0.0,
0.0
]
},
"target": { // The location of the target
"position": [
1.5,
3.4,
1.5
],
"view_vector": [ // Points back towards the listener
0.0,
-0.9,
0.0
]
},
"dataset": "eval" // Ca be train, dev or eval
},
... // more rooms
]
Some points to note are:
- All times in the
scenes.jsonfile are measured in samples at 48000 Hz. - In order to simulate the hearing aid signals, the HRIRs are taken from the OlHeadHRTF database with permission . Different scenes have used different heads as indicated by the
hrir_filenamefield. - For indoor responses, the listener location as measured in the 13.3 m by 6 m room with the origin at the botton left corner of the plan view. For outdoor responses, the x and y coordinates are recorded as 0, 0. The height is always 1.5 m.
- For external responses, the dimension field contains "13.3 m x 6 m" - this is an error and should be ignored.
The Background Metadata
The ambisonic background recordings metadata is stored in a JSON file as a list of dictionaries. The format is as follows,
[
{
"filename": "cec3_station_S01_001_hoa.wav", // The filename where the background is stored
"session": "S01", // The recording session ID
"index": 1, // A unique index for the background recording within the session
"type": "station", // The type of background noise (can be 'party', 'road', 'station')
"ir_location": "external", // The compatible IR location (see note below)
"duration": 28.672, // Duration in seconds
"nsamples": 1376256, // Number of samples (at 48000 Hz sampling rate)
"dataset": "train", // The dataset it belongs to [train, dev, eval]
},
... // more backgrounds
]
Notes,
- The session ID is a unique identifier for the recording session. Most of the sessions resulted in the recording of multiple background noise files.
- The
ir_locationfield indicates which target impulse responses can be paired with this background. For station and road this will be 'external'. For the party backgrounds it will beparty_<SESSION>, i.e., for the party recordings there are paired backgrounds and IRs for each recording session, and each session is represents a different recording location in the room. Their_locationfield will also appear in theroommetadata, i.e., providing a clear link between the backgrounds and IRs.
References
Farina, A. (2007). Advancements in impulse response measurements by sine sweeps. Proceedings of 122nd AES Convention, Vienna.