Task 2 Data
The Task 2 data consists of real acoustic scenes that have been recorded over hearing aid shells, each with three channels (front, middle, back). The scenes are based on the domestic environments used in previous Clarity challenges consisting of a target sentence and either two or three interferers. The interferers can be speech, music or noise from domestic appliances in any combination. Data has been split into two sets: 6,000 scenes for training and a 2,500 scene development set. A further 1,500 scenes were recorded and have been set aside for evaluation.
The data is organised into the following directories, and can be obtained from the download page.
clarity_CEC3_data
|── manifest
|── task1
|── task2
| └── clarity_data
| |── metadata - metadata for each scene
| |── train
| | |── scenes - audio and headtracking data for training scenes
| | |── interferers - complete set of interferer signals available for training
| | └── targets - complete set of target signals available for training
| └── dev
| |── scenes
| |── interferers
| |── targets
| └── speaker_adapt - speaker adaptation utterances (see below)
└── task3
The sections below describe the recording setup, the format of the audio and headtracking data, and the metadata provided for each scene.
Recording setup
The scenes were recorded over the period of two weeks in a recording room at the University of Sheffield. The target and interferer signals were played using a set of 13 loudspeakers arranged around a listener. The listener was wearing hearing aid shells with three microphones (front, middle, back) and a pair of glasses with reflective markers that were tracked with a Vicon motion capture system. Nine loudspeakers were placed in front of the listener arranged at semi-randomly selected locations on a polar grid (the grid has distances of 2 m to 4 m spaced at 0.5 m and angles from -60 degrees to 60 degrees spaced at 7.5 degrees). The remaining four loudspeakers were placed in a line behind the listener. For each scene, one of the front loudspeakers was chosen to play the target utterances, and two or three of the 12 remaining speakers (front and back) were chosen to play the interferers.
- Recording Room
- ...another view
- ... and another.

(The four rear loudspeakers are not visible in this in this view.)


Scenes were recording in blocks of 125 where each block had the same target speaker and the same speaker locations. The front speakers were labelled 1 to 9 so that they could be easily identified by the listener. For each scene one of the 9 front speakers, other than the target speaker, was chosen as the initial look direction speaker. Before the scene is played, the look-direction speaker plays its number and the listener is instructed to turn to face it. Then after a short pause the multisource scene plays. Within the scene, the target speaker starts about two seconds after the interfering noise sources. The listener is asked to attend to the target speech source and turn to face it when it starts, and also to note down the speaker number. This process is repeated 125 times with a short pause between scenes. The entire block recording lasts about 20 minutes and once recording is complete the audio and headtracking data is segmented into individual scenes.
After each recording block the front speakers are moved to a new set of locations on the grid. Each of the 80 blocks has its own unique speaker layout. The speaker locations were randomised such there was only ever one loudspeaker along each radial direction and that the loudspeaker were spread across the full range of angles. Some examples are shown below. The precise locations of the speakers are provided in the metadata for each scene.






Following CEC2, the scenes were designed to produce a large range of SNRs for the target. This was set to be between -12 dB and 6 dB in the condition that all the loudspeaker signals are instantaneously added. Note, the actual SNRs recorded at the microphones will vary further depending on the rooms acoustics and the listeners head rotation etc, e.g., SNRs will be higher than that recording in the meta data if the target is closer to the listener than the interferers, and lower if the target is further away. (We plan to release estimates of the SNRs at the microphones in the future.)
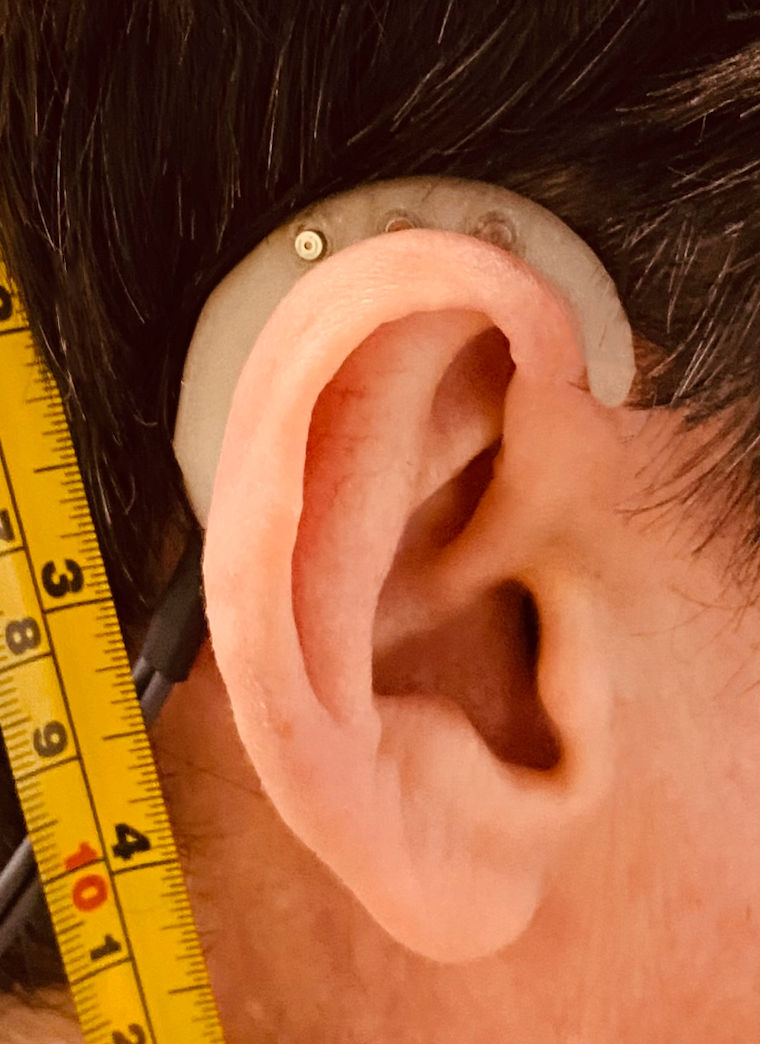
The signals were recorded using hearing aid shell with three microphones (front, middle and back). The figure below shows how these are positions when the shell are being worn. The microphones are each about 1 cm apart and form an approximately horizontal line when the head it level. Click on the image to enlarge.

Audio and Headtracking Data format
All audio data is provided in 16-bit PCM format at a sample rate of 48000 kHz. File names have been designed to be compatible with previous Clarity challenges. For each scene the following audio files are provided:
- <SCENE_ID>_mix_CH1.wav - the left and right stereo pair from the front microphone.
- <SCENE_ID>_mix_CH2.wav - the left and right stereo pair from the middle microphone.
- <SCENE_ID>_mix_CH3.wav - the left and right stereo pair from the back microphone.
- <SCENE_ID>_target.wav - the target speech signal.
- <SCENE_ID>_interferer.wav - the interferer signals stored as either 2 or 3 channel audio files.
- <SCENE_ID>_reference.wav - the signal to be used as the reference for HASPI evaluation.
These signals are provided for both the training and development data set. When the evaluation data is released only the mix files will be provided.
The headtracking data is provided in a CSV file with a frame rate of 250 Hz,
- <SCENE_ID>_hr.csv - the audio-aligned 6 DOF head track
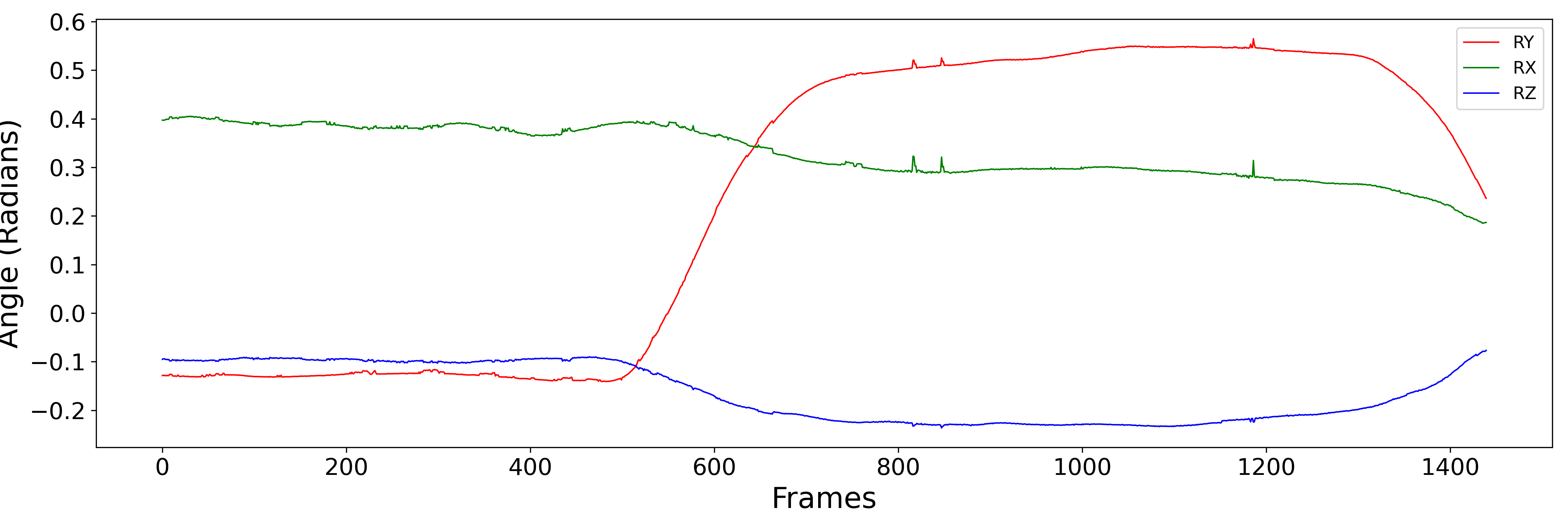
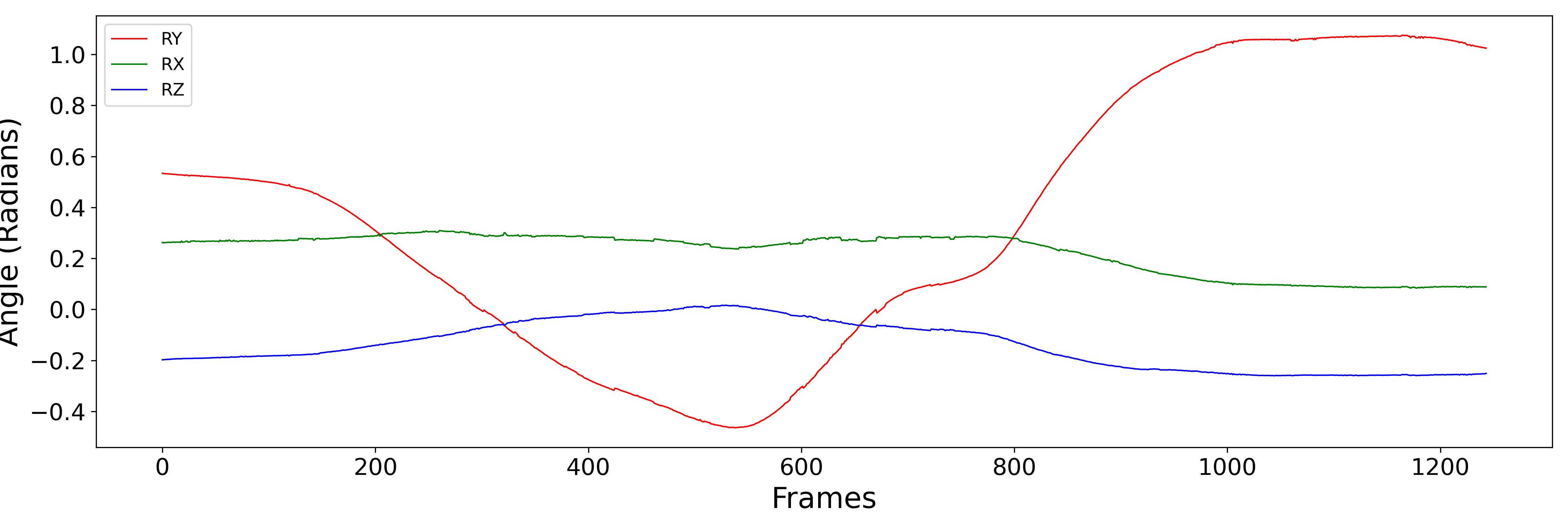
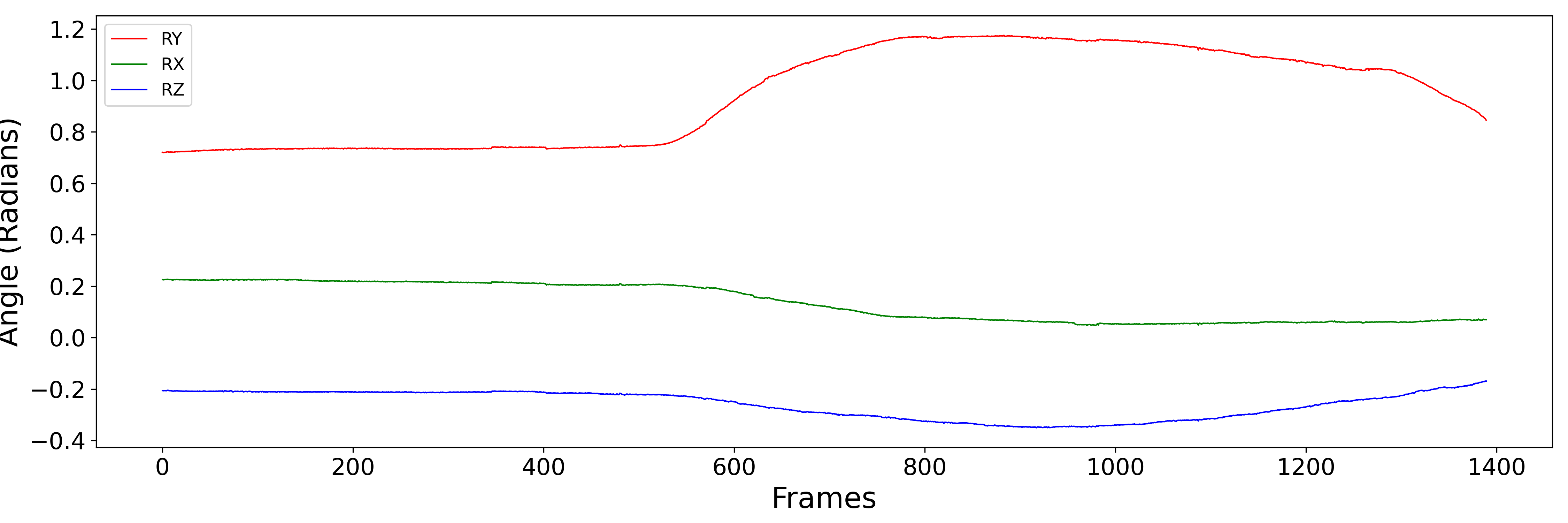
The headtracking has been carefully aligned with the audio recordings. The csv files have six columns: TX, TY, TZ, RX, RY and RZ. (TX, TY, TZ) are the locations of the head with respect to the tracker origin. (RX, RY, RZ) is the rotation of the head with respect to a level, forward facing head. The angles are stored in radians in `helical' form, i.e. they represent a vector whose direction is the axis of rotation and whose magnitude is the size of the rotation in radian. The figure below plots the raw RX, RY and RZ data for three different scenes. Note, the helical representation makes interpretation a little difficult, but broadly speaking RY is the head turning left to right, RX is the head tipping up and down and RZ is the head tilting.
- Head rotation example
- ...and another
- ... and another.
The headtracking data is provided for both the training and development data set and will be provided for optional use during evaluation as well.
Speaker adaptation data
The scenes that you have been asked to enhance often contain speech signals as interferers. This means that the task of enhancing the target speaker is ambiguous unless you are told which of the speakers to use as target. In this task, we follow the approach used in CEC2 and provide a small set of clean target speaker example utterances. So, for each scene, the ID of the target speaker is provided in the metadata, and systems can then use the examples and select the target as the one that has the matching voice.
Note, these same utterances will be used in the final subjective listening tests, i.e. the listeners will be presented with the examples before listening to the processed signal and told that these are examples of the target speaker that they are meant to be listening to.
Metadata Formats
The following metadata files are provided
# The description of the scenes
- scenes.[train|dev].json - metadata for the training/dev scenes
- rooms.[train|dev].json - metadata for the training/dev rooms
# Listener information
- scenes_listeners.dev.json - the listeners/scene pairings to for the standard development set
- listeners.json - the audiograms of the listeners
# Materials used to make up the scenes
- masker_music_list.json - the list of music interferers
- masker_nonspeech_list.json - the list of non-speech interferers
- masker_speech_list.json - the list of speech interferers
- target_speech_list.json - the list target utterances
Most of these files follow the same format as in CEC2. The most important are the scenes.json and rooms.json files and these are described below.
The room describes the locations of the 13 loudspeaker and the listener. There are 80 different 'rooms' corresponding to the 80 different recording sessions, each of which had their own speaker layout. The 'scenes' are represented by a 'room' (i.e., a loudspeaker configuration) and a description of the target and interferers and which of the loudspeakers they were played from. Note, there is a one-to-many relationship between rooms and scenes, i.e., each room is used to record 125 different scenes. However, different subsets of the loudspeakers are used for each scene, so few scenes will have the target and maskers in the same location.
The room' andscene' metadata files are described in more detail below.
The Room Metadata
The room metadata is stored in a JSON file as a list of dictionaries, with one dictionary representing each room. The format is as follows:
[
{
"name": "R001", // The Room identifier (R001 to R080)
"dimensions": "6.0x6.0x3.0", // Approximate room dimensions (fixed)
"sources": [ // A list of the 13 loudspeaker locations
{
"position": [
-2.5981, // In x,y,z coordinate but map onto the polar grid
1.5,
1.4 // This is the approximate height of the loudspeakers and is fixed
],
"view_vector": [ // Loudspeakers all directed towards listener
2.5981,
-1.5,
0.0
]
},
// etc, 13 source positions in total
]
"listener": [
{
"position": [ // Note the origin is at the listener location
0.0,
0.0,
1.4
],
"view_vector": [ // For compatibility with CEC2 but replace with headtracking data
0.0,
1.0,
0.0
]
}
]
},
... // more rooms
]
The Scene Metadata
The scene metadata is stored in a JSON file as a list of dictionaries with one dictionary for each scene. There are 6000 scenes in the training set and 2500 in the development set. A further 1500 have been retained for the final evaluation.
[
{
"scene": "S00508", // The Scene ID (S00001 to S10000)
"target": { // The target description
"name": "T001_FRD_00503", // The utterance ID which starts with the talker ID (T001 to T040)
"time_start": 77020, // The sample at which the target starts
"time_end": 176245, // The sample at which the target ends
"position": 7, // The loudspeaker number (indexed 1 to 13). The location is in the rooms metadata.
"dataset": "train" // Can be train, dev or eval
},
"interferers": [ // The list of interferers. Either two or three.
{
"name": "scm_08421", // The interferer ID
"time_start": 0, // The sample at which the interferer starts (always 0)
"time_end": 220345, // The sample at which the interferer ends (always the end of the scene)
"position": 3, // The loudspeaker number (indexed 1 to 13). The location is in the rooms metadata.
"dataset": "train", // Can be train, dev or eval
"type": "speech", // The type of interferer (speech, music, noise)
"offset": 10306318 // The offset of the interferer in the complete audio file
},
{
"name": "nom_03397",
"time_start": 0,
"time_end": 220345,
"position": 10,
"dataset": "train",
"type": "speech",
"offset": 15349869
}
],
"listener": { // The listener information
"ID": "L001", // The listener ID (always L001)
"initial_head_orientation": 3 // The initial look direction (1 to 9)
},
"room": "R001", // The Room ID (R001 to R080) which provides the loudspeaker locations
"SNR": -1.1145819681656075, // The SNR of the target signal (-12 to 6 dB)
"duration": 220345, // The duration of the scene in samples
"dataset": "train" // Can be train, dev or eval
},
Some important points to note are:
- The timing of events is recorded in samples at 44100 Hz. This was the sampling rate at which all the audio target and interferer materials are stored and so was used for scene construction. However, signals were then upsampled to 48 kHz to meet the specification of the recording and playback hardware in the recording room. So take care to convert the sample numbers to the correct rate if you are using them to analyse the audio, e.g. to endpoint the target speech.
- The SNR is not the SNR at the microphones. It is the SNR that would be obtained if the signals delivered to the loudspeakers were summed instantaneously (i.e. without any room acoustic effects). They can be used as a rough guide. We plan to produce estimates of the true SNRs later in the challenge to allow for more accurate performance evaluation. The SNR is computed over the duration of the target signal and using a speech weighted filter. The signal generation code will be made available in the GitHub repository.