ICASSP 2023 Data
To obtain the data and baseline code, please see the download page.
A. Training, development and evaluation data
The dataset of 10,000 simulated scenes is split into three sets:
- 6000 training scenes (available now)
- 2500 development scenes (available now)
- 1500 evaluation scenes (released 1st Feb. 2023)
In addition there will be:
- A secondary 'real data' evaluation set that will be based on real ecologically-valid recordings and so can highlight the generalizability of the entrants’ approaches beyond the simulations (released 1st February 2023). More information.
B. The scene dataset
For the dataset of 10,000 simulated scenes
- Each scene corresponds to a unique target utterance and unique segment(s) of noise from the interferers.
- The training, development and evaluation sets are disjoint with respect to the target speakers.
- Sets are balanced for the gender of the target talker.
- Entrants must not use the development or evaluation data sets for training.
- The system submitted should be chosen on the evidence provided by the development set.
For evaluation
- The final ranking will be performed with the (held-out) evaluation sets.
- Neither evaluation datasets (simulation nor real) have been used in previous Clarity challenges.
- The secondary 'real data' evaluation set will be made using real acoustic mixtures but using loudspeaker playback of target talkers so that the reference speech can be extracted as needed by the objective metrics.
For the training and development set, entrants have access to a diverse range of signals and metadata, with the most important being:
- The hearing aid microphone signals
- The hearing characteristics of the listener (e.g. audiogram)
- The anechoic target reference and interferer signals.
For training, teams can not use external data but can expand the official training data through automated modifications and remixing, i.e. data augmentation strategies. However, teams that do this must make a second submission using only the official audio files.
For evaluation, the data available is more limited, i.e.,
- The hearing aid microphone signals
- The hearing characteristics of the listener (e.g. audiogram)
- The anechoic target reference signal which will be used by the organisers but not released to entrants.
High-Order Ambisonic Impulse Responses (HOA-IRs) and Head-Related Impulse Response (HRIRs) are used to model how the sound is altered as it propagates through the room and interacts with the head. See the page on scene generation for more details.
Time-domain acoustic signals are generated for:
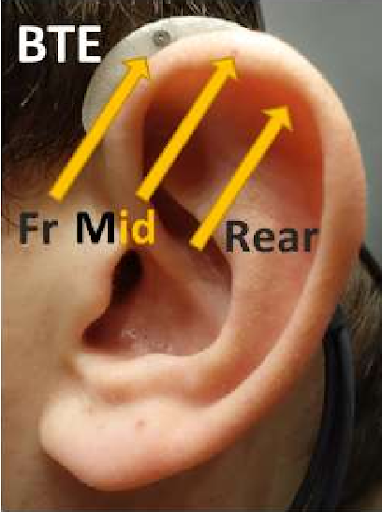
- A hearing aid with 3 microphone inputs (front, mid, rear). The hearing aid has a Behind-The-Ear (BTE) form factor; see Figure 1. The distance between microphones is approx. 7.6 mm. The properties of the tube and ear mould are not considered.
- Close to the eardrum.
- The anechoic target reference (front microphone).
Head Related Impulse Responses (HRIRs) are used to model how sound is altered as it propagates in a free-field and interacts with the head (i.e., no room is included). These are taken from the OlHeadHRTF database with permission. These include HRIRs for human heads and for three types of head-and-torso simulator/mannekin. The eardrum HRIRs (labelled ED) are for a position close to the eardrum of the open ear.
rpf files and ac files are specification files for the geometric room acoustic model that include a complete description of the room, both in terms of geometry and room materials.
B.1 Training data
For each scene in the training data the following signals and metadata are available:
- The target and interferer HOA-IRs (4 pairs: front, mid, rear and eardrum for left and right ears).
- The mono target and interferer signals (pre-convolution).
- For each hearing aid microphone (channels 1-3 where channel 1 is front, channel 2 is mid and channel 3 is rear) and a position close to the eardrum (channel 0):
- The target convolved with the appropriate HOA-IRs and downmixed;
- The interferers convolved with the appropriate HOA-IRs and downmixed;
- The sum of the target and interferer convolved with the appropriate HOA-IRs and downmixed; (i.e. the noisy signals that would be received by the hearing aid)
- The target convolved with the anechoic HOA-IRs and downmixed for channel 1 for each ear (‘target_anechoic’). For use as a reference when computing HASPI scores.
- Metadata describing the scene: a JSON file containing, e.g., the filenames of the sources, the location of the sources, the viewvector of the target source, the location and viewvector of the receiver, the room dimensions (see specification below), and the room number, which corresponds to the RAVEN BRIR, rpf and ac files.
- A signal describing the head rotation (i.e. azimuthal angle at each sample)
B.2 Development data
This is made available to allow you to fully examine the performance of your system. Ground truth data (i.e., the premixed target and interferers are available in the development set)
Development data also contains target speaker adaptation sentences, i.e., four utterances from each of the target speakers. These will also be available in the evaluation data. i.e., systems can use these utterances in conjunction with the known target ID to inform their system of the which speaker in the scene should be attended.
Note, that the data available for the evaluation will be much more limited, e.g. it will not contain premixed ground truth signals or scene metadata, (see Section B.3).
When using the development data for evaluation, your hearing aid enhancement model should only be using the types of data available in the evaluation data set (see below).
B.3 Simulated Evaluation data (eval1)
The following data will only be available:
- Audio: the sum of the target and interferers for each hearing aid microphone.
- The ID of the listener who will be auditioning the processed scene.
- The listener characterisation data for these listeners.
- ID of target talker and a few examples of clean audio that are not the same as the target utterance.
- The head rotation signal, i.e. as might be recovered from hearing aid motion sensors. (Systems can use this signal but should also be evaluated without using it.)
- Speaker adaptation sentence - 4 clean utterances for each target speaker.
One challenge will be identifying the target talker from the hearing aid microphone signals. There are two possibilities:
- The ID of the target talker is given with examples of clean audio. This would allow an algorithm to learn characteristics of the target talker to then help it identify the voice in the mixture.
- The azimuth of the target and the starting time of the utterance are both roughly known from the scene generation metadata statistics.
These two approaches mimic what is available to human listeners. They might focus on a known voice or they might use visual cues to know roughly where and when someone is talking.
B.4 Real Evaluation data (eval2)
The following data will only be available:
- Audio: the sum of the target and interferers for each hearing aid microphone.
- The ID of the listener who will be auditioning the processed scene.
- The listener characterisation data for these listeners.
- ID of target talker and a few examples of clean audio that are not the same as the target utterance.
- Speaker adaptation sentence - 4 clean utterances for each target speaker.
- Further details to be confirmed.
C Listener data
We will provide metadata characterising the hearing abilities of the listeners so the audio signals you generate for evaluation can be individualised to the specific listeners who will be hearing them.
The same types of data are available for training, development and evaluation.
A panel of hearing-aided listeners will be recruited for evaluation. They will be experienced bilateral hearing-aid users: they use two hearing aids but the hearing loss may be asymmetrical. The average pure tone air-conduction hearing loss will be between 25 and about 60 dB in the better ear. They will be fluent in British English.
The quantification of the listeners’ hearing is done with:
- Left and right pure tone air-conduction audiograms. These measure the threshold at which people can hear a pure-tone sound.
- Results from the DTT (digit-triplet test, also known as a triple digit test)
The audiogram is the standard clinical measurement of hearing ability. It’s the pure-tone threshold of hearing in each ear, measured in quiet in a sound booth. The procedure is standardized e.g., British Society of Audiology Recommended Procedure. Typically it’s measured at octave frequencies and important intermediate frequencies.The values of the audiogram defines how much gain the hearing aid needs to apply, with the calculation typically done by one of a group of "prescription rules", e.g. CAMFIT, NAL-NL2 or DSL .
Note that the scale of an audiogram is in “dB HL” = “dB Hearing Level”. This is not dB SPL; instead, it’s relative to an international standard such that 0-dB is “normal hearing” at every frequency. For background see Why the Audiogram Is Upside-down | The Hearing Review and The Quest for Audiometric Zero | The Hearing Review
The DTT is an adaptive test of speech-in-noise ability. In each trial a listener hears three spoken digits (e.g. 3-6-1) against a background of noise at a given signal-to-noise-ratio (SNR). The task is to respond on a keypad with those three digits in the order they were presented. If the listener gets all three correct, then the SNR is reduced for the next trial so making it slightly harder. If the listener makes any mistake (i.e., any digit wrong, or the order wrong) then the SNR is increased, so making the next trial slightly easier. The test carries on trial-by-trial. The test asymptotes to the SNR at which the participant is equally likely to get all three correct or not, with a few tens of trials needed to get an acceptable result. DTT tests are now used world-wide to measure hearing as they are easy to make in any local language, to explain to participants and to do, and moreover can be done over the internet or telephone as they measure a relative threshold (signal-to-noise ratio), not an absolute threshold in dB SPL. Listeners are encouraged to set a volume that is comfortable and that does not distort or crackle, but is not too quiet.
This paper is a recent scoping review of the field. The particular version we used is Vlaming et al.'s high-frequency DTT, which uses a high-pass noise as the masker. Ours starts at -14 dB SNR, goes up/down at 2 dB steps per trial, and continues for 40 trials.
In the datafile, an average of the SNR for the last 30 trials is provided (labelled 'threshold'). For reference, the SNRs are supplied for each trial as well. The very first trial is practice and is not scored.
D Data file formats and naming conventions
D.1 Abbreviations used in filenames
The following abbreviations are used consistently throughout the filenames and references in the metadata.
R– “room”: e.g., “R02678” # Room ID linking to RAVEN rpf fileS– “scene”: e.g., S00121 # Scene ID for a particular setup in a room I.e., room + choice of target and interferer signalsBNC– BNC sentence identifier e.g.BNC_A06_01702CH–CH0– eardrum signalCH1– front signal, hearing aid channelCH2– middle signal, hearing aid channelCH3– rear signal, hearing aid channel
I/i1– Interferer, i.e., noise or sentence ID for the interferer/maskerT– talker who produced the target speech sentencesL– listenerE– entrant (identifying a team participating in the challenge)t– target (used in BRIRs and RAVEN project ‘rpf’ files)
D.2 General
- Audio and HOA-IRs will be 44.1 kHz 32-bit wav files in either mono or stereo as appropriate.
- Where stereo signals are provided the two channels represent the left (0) and right (1) signals of the ear or hearing aid microphones.
- 0 dB FS in the audio signals corresponds to 100 dB SPL.
- Metadata will be stored in JSON or csv format as appropriate with the exception of
- Room descriptions are stored as RAVEN project ‘rpf’ configuration files and ‘ac’ files. (However, key details are reflected in the scene.json files)
- Signals are saved within the Python code as 32-bit floating point by default.
- Output signals for the listening tests will be required to be in 16-bit format.
D.3 Prompt and transcription data
The following text is available for the target speech:
- Prompts are the text that was given to the talkers to say.
- ‘Dot’ transcriptions contain the text as it was spoken in a form more suitable for scoring tools.
- These are stored in the master json metadata file.
D.4 Source audio files
Wav files containing the original source materials. Original target sentence recordings:
<Talker ID>_<BNC sentence identifier>.wav
D.5 Preprocessed scene signals
Audio files storing the signals picked up by the hearing aid microphone that are ready for processing. Separate signals are generated for each hearing aid microphone pair or ‘channel’.
<Scene ID>_target_<Channel ID>.wav<Scene ID>_interferer_<Channel ID>.wav<Scene ID>_mixed_<Channel ID>.wav<Scene ID>_target_anechoic.wav- at hearing device front microphone<Scene ID>_hr.wav- head rotation signal
Scene ID – S00001 to S10000
- S followed by 5 digit integer with 0 pre-padding
Channel ID
- CH0 – Eardrum signal
- CH1 – Hearing aid front microphone
- CH2 – Hearing aid middle microphone
- CH3 – Hearing aid rear microphone
The anechoic signal is the signal that will be used as the referernce in the HASPI evaluation.
The head rotation signal indicates the precise azimuthal angle of the head at each sample. It is stored as a floating point wav file with values between -1 and +1 where the range maps linearly from -180 degrees to +180 degrees. Teams are free to use this signal in their hearing aid algorithms, but if you do so we will ask you to also submit a version of your system that does not use it, so that the benefit of known head motion can be measured.
D.6 Enhanced signals
The signals that are output by the baseline enhancement algorithm.
<Scene ID>_<Listener ID>_enhanced.wav# Enhancement output signal (i.e., as submitted by the challenge entrants)
Listener ID – ID of the listener panel member, e.g., L001 to L100 for initial ‘pseudo-listeners’, etc.
D.7 Hearing-aid output signals
<Scene ID>_<Listener ID>_HA-output.wav# i.e., the enhanced signals after processing with the supplied hearing aid amplification.
Listener ID – ID of the listener panel member, e.g., L001 to L100 for initial ‘pseudo-listeners’, etc.
D.8 Room metadata
JSON file containing the description of a room. This is the data from which the ambisonic room impulse response are generated. It stores the fixed room, listener, target and interferer geometry but does not specify the dynamic factors (e.g. signals, SNRs, head movements etc) that are needed to fully define a scene.
[
{
"name": "R00001", // ID of room linking to RAVEN rpf and ac files
"dimensions": "6.9933x3x3", // Room dimensions in metres
"target": { // target positions (x,y,z) and view vectors (look directions, x,y,z)
"position": [-0.3, 2.4, 1.2],
"view_vector": [0.071, 0.997, 0.0],
},
"listener": {
"position": [-0.1, 5.2, 1.2],
"view_vector": [0.071, 0.997, 0.0],
},
"interferers": [
{
"position": [0.4, 4.0, 1.2],
},
{ // etc, up to three interferers
}
],
},
...
]
D.9 Scene metadata
JSON file containing a description of the scene. It is a list of dictionaries with each entry representing a unique scene. A scene can be considered to be a room (see Section D.7) plus the full set of listener, target and interferer details. Note, many scenes can be generated from a single room, i.e. each using different listener, target and interferer settings.
[
{
"scene": "S00001", // the unique scene ID
"room":: "R00001", // ID of room linking to rooms.json
"target": {
"name": "T005_JYD_04274", // target speaker code and BNCid
"time_start": 107210, // start time of target in samples
"time_end": 217019 // end time of target in samples
},
"listener": {
"rotation": [ // Defines the head motion - list of time, direction pairs
{
"sample": 88200,
"angle": 30 // Azimuth angle in degrees
},
{
"sample": 176400,
"angle”: 50
}
],
"hrir_filename":
["VP_N4-ED",
"VP_N4-BTE_fr",
"VP_N4-BTE_mid",
"VP_N4-BTE_rear"] // HRIR filename for each channel to generate
},
"interferers": [
{
"position": 1, // Index of interferer position (See rooms.json)
"time_start": 0, // time of interferer onset in samples
"time_end": 261119, // time of interferer offset in samples
"name": "track_1353255", // interferer name
"type": "music", // interferer type: speech, noise or music
"offset": 4076256 // index into interferer file at which to extract sample
},
{ // etc, up to three interferers
}
],
"dataset": "train", // the dataset to which the scene belongs: train, dev or eval
"duration": 261119, // total duration of scene in samples
"SNR": 6.89 // targe SNR for the scene
},
...
]
There are JSON files containing the scene specifications per dataset, e.g., scenes.train.json.- Note, that the scene ID and room ID might have a one-to-one mapping in the challenge, but are not necessarily the same. Multiple scenes can be made by changing the target and masker choices for a given room. E.g., participants wanting to expand the training data could remix multiple scenes from the same room.
The listener ID is not stored in the scene metadata; this information is stored separately in a scenes_listeners.json file which maps scenes to listeners, ie. telling you which listener (or listeners) will be listening to which scenes in the evaluation (see Section D.9).
Noise interferers are labelled with a type “music”, “noise” or “speech” and then have a unique name identifying the file.
- For speech:
<ACCENT_CODE>_<SPEAKER_ID>whereACCENT_CODEis a three letter code identify the accent region and gender of the speaker andSPEAKER_IDis a 5-digit ID specific to an individual speaker. E.g. "mif_02484" is a UK midlands accented female, speaker 02484. The speech comes from Demirshan et al. [1] which provides more details. - For noise:
CIN_<NOISE_TYPE>_<NOISE_ID>whereNOISE_TYPEis one ofdishwasher,fan,hairdryer,kettle,microwave,vacuum(vacuum cleaner) orwashing(washing machine) andNOISE_IDis a unique 3-digit code for the sample. - For music:
track_<TRACK_ID>whereTRACK_IDis unique 7-digit track identifier taken from the MTG Jamendo database. [2]
Given the type and name, further interferer metadata can be found in the files masker_speech_list.json, masker_noise_list.json and masker_music_list.json which are distributed with the challenge.
D.10 Listener metadata
Audiogram data is stored in a single JSON file with the following format.
{
"L0001": {
"name": "L0001",
"audiogram_cfs": [250, 500, 1000, 2000, 3000, 4000, 6000, 8000],
"audiogram_levels_l": [10, 10, 20, 30, 40, 55, 55, 60],
"audiogram_levels_r": [ … ],
},
"L0002": {
// ... etc
},
// ... etc
}
Additional metadata (e.g. digit triple test results) are stored in a csv file. DETAILS
D.11 Scene-Listener map
JSON file named scenes_listeners.json dictates which scenes are to be processed by which listeners.
{
"S00001": ["L0001", "L0002", "L0003"],
"S00002": ["L0003", "L0005", "L0007"],
// ... etc
}
References
- Demirsahin, Isin and Kjartansson, Oddur and Gutkin, Alexander and Rivera, Clara, "Open-source Multi-speaker Corpora of the English Accents in the British Isles", Proceedings of The 12th Language Resources and Evaluation Conference (LREC), 6532--6541, 2020, Avialable Online
- Bogdanov, Dmitry and Won, Minz and Tovstogan, Philip and Porter, Alastair and Serra, Xavier, "The MTG-Jamendo Dataset for Automatic Music Tagging", In Proc. Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019), 2019, Long Beach, CA, United States", Available Online