CPC1 Data
To obtain the data and baseline code, please visit the download page.
A. Training, development, evaluation data
The dataset is split into these two subsets: training/development (train) and evaluation (eval).
- You are responsible for splitting the training/development dataset into data for training and development, e.g., using k-fold cross validation.
- The final evaluation and ranking will be performed with the (held-out) evaluation set.
- For more information on supplementing the training data, please see the rules, and also the FAQ. The evaluation dataset will be made available one month before the challenge submission deadline.
B. The scene dataset
The complete dataset is composed of a large number of scenes associated with 6 talkers, 10 hearing aid systems and around 25 listeners.
Each scene corresponds to a unique target utterance and a unique segment of noise from an interferer. The training/development and evaluation sets are disjoint for system and listener.
Binaural Room Impulse Responses (BRIRs) are used to model how the sound is altered as it propagates through the room and interacts with the head. The audio signals for the scenes are generated by convolving source signals with the BRIRs and summing. See the page on modelling the scenario for more details. Randomised room dimensions, target and interferer locations are used. RAVEN is the geometric room acoustic model used to create the BRIR.
B.1 Training/development data
This contains all the information about how the signals processed by the hearing aids were created. For the prediction challenge, some of the data can be ignored (but is included because some may find it useful).
Data and metadata most useful for the prediction challenge:
- The output of the hearing aid processor.
- The target convolved with the anechoic Binaural Room Impulse Response (BRIR) (channel 1) for each ear (‘target_anechoic’).
- The mono target and interferer signals (pre-convolution).
- Prompts of the utterances (what the actors were told to say)
- Metadata describing the scene: a JSON file containing, e.g., the filenames of the sources, the location of the sources, the viewvector of the target source, the location and viewvector of the receiver, the room dimensions (see specification below), and the room number, which corresponds to the RAVEN BRIR, rpf and ac files.
For evaluation not all of the data is available, see below.
Other information also provided, click me to expand
Data used to create inputs to hearing aids, etc:
- The target and interferer BRIRs (4 pairs: front, mid, rear and eardrum for left and right ears).
- Head Related Impulse Responses (HRIRs) including those corresponding to the target azimuth.
- For each hearing aid microphone (channels 1-3 where channel 1 is front, channel 2 is mid and channel 3 is rear) and a position close to the eardrum (channel 0):
- The target convolved with the appropriate BRIR;
- The interferer convolved with the appropriate BRIR;
- The sum of the target and interferer convolved with the appropriate BRIRs.
The BRIRs are generated for:
- A hearing aid with 3 microphone inputs (front, mid, rear). The hearing aid has a Behind-The-Ear (BTE) form factor; see Figure 1. The distance between microphones is approx. 7.6 mm. The properties of the tube and ear mould are not considered.
- Close to the eardrum.
- The anechoic target reference (front microphone; the premixed target signal convolved with the BRIR with the reflections “turned off”).
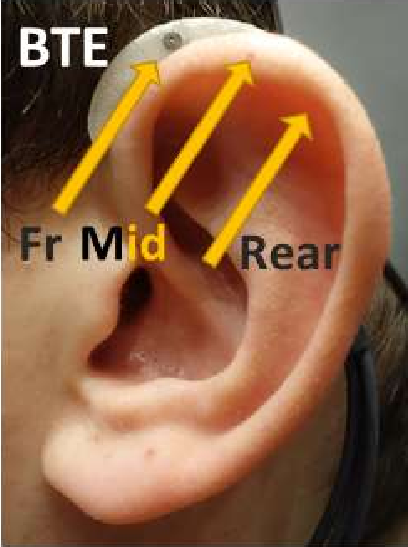
(HRIRs) are used to model how sound is altered as it propagates in a free-field and interacts with the head (i.e., no room is included). These are taken from the OlHeadHRTF database with permission. These include HRIRs for human heads and for three types of head-and-torso simulator/mannekin. The eardrum HRIRs (labelled ED) are for a position close to the eardrum of the open ear.
The RAVEN project files - termed "rpf" - are specification files for the geometric room acoustic model that include a complete description of the room.
B.2 Evaluation scene data
For each scene in the evaluation data only the following will be available:
- The output of the hearing aid processor.
- The target convolved with the anechoic BRIR (channel 1) for each ear (‘target_anechoic’).
- The IDs of the listeners assigned to the scene/hearing aid system in the metadata provided.
- The listener metadata.
- The prompt for the utterances (the text the actors were given to read)
C Listener data
We will provide metadata characterising the hearing abilities of our listening panel. The listening panel data will be split, so that the listeners in the held back evaluation data are different from those provided in the training and development data. The listening panel are experienced bilateral hearing-aid users (they use two hearing aids but the hearing loss may be asymmetrical) with an averaged hearing loss as measured by pure tone air-conduction of between 25 and about 60 dB in the better ear, with fluent speaking of (and listening to) British English.
-
For every listener, you will be given the left and right pure tone air-conduction audiograms. These measure the threshold at which people can hear a pure-tone sound.
-
For some listeners you will be provided with additional characterisation of their hearing. Consequently, if you wish to exploit this additional data, you will need to deal with the missing data. See the FAQ for more on missing data. Below is a description of each measure.
SSQ12 - Speech, Spatial, & Qualities of Hearing questionnaire, 12-question version
This is a popular self-assessment questionnaire of hearing disability. Each item asks about listening situations typical of real life and asks how well a listener would do in it. The SSQ assesses ability to make successful use of one’s hearing (i.e. hearing disability, or activity limitation). This is an intermediate link between the audiological measurement of someone's hearing loss (i.e. their impairment) and a patient's assessment of how that hearing loss impacts their wider life (i.e. their handicap, or participation restriction). The 12 questions are given in table 1 of this paper and FYI a recent paper that used it is here.
Responses to each question are on a scale from 0 to 10, with 0 representing "not at all" (or "jumbled"/"concentrate hard" for #11 & #12), and 10 representing "perfect" (or "not jumbled"/"no need to concentrate"). We programmed this as a visual-analog slider, which the participant could set to any position from 0 to 10. The SSQ12 data supplied are the responses to each question, from 0-10 at 1 decimal place resolution, along with the mean of all 12 questions.
GHAPB - Glasgow hearing-aid benefit profile questionnaire
This is designed to assess the efficacy and effectiveness of someone's hearing aid(s) in different scenarios. It asks respondents to consider four scenarios involving speech and to rate on a five-point scale their perceived initial (i.e. unaided) hearing disability, initial handicap, aided benefit, aided handicap, hearing aid use, and hearing aid satisfaction. The listening panel are experienced hearing-aid users, so some of the rating would be about their normal hearing aid. This paper describes the GHABP and provides some normative data.
For each scenario, the participant is asked a primary question about if a situation happens to them (relatable). If they answer
- No, it moves onto to the next scenario.
- Yes, then a list of six secondary questions are asked (see figure below)
- If one of the secondary questions is not relatable to the participant, they're asked to respond "N/A" for not applicable.

There are four scenarios:
- listening to the television when the volume is adjusted for others.
- Having a conversation with one person in quiet.
- Having a conversation on a busy street or in a shop.
- Having a conversation with several people in a group.
In the datafile, the question numbers are coded as x.y where x is the scenario number and y the secondary question number.
If the answer to primary questions is No, then all the secondary questions are coded as 0.
If the answer to primary questions is Yes, then each subsequent question is scored as 0. = N/A
- = first option in the list (eg "no difficulty")
- = second
- = third
- = fourth
- = fifth (e.g. "cannot manage at all")
There is no global score for the GHABP. The six secondary questions ask about different things and so should not be averaged across questions, though it is fairly common to average within-question across scenario.
DTT (digit-triplet test, also known as a triple digit test)
This is an adaptive test of speech-in-noise ability. In each trial a listener hears three spoken digits (e.g. 3-6-1) against a background of noise at a given signal-to-noise-ratio (SNR). The task is to respond on a keypad with those three digits in the order they were presented. If the listener gets all three correct, then the SNR is reduced for the next trial so making it slightly harder. If the listener makes any mistake (i.e., any digit wrong, or the order wrong) then the SNR is increased, so making the next trial slightly easier. The test carries on trial-by-trial. The test asymptotes to the SNR at which the participant is equally likely to get all three correct or not, with a few tens of trials needed to get an acceptable result. DTT tests are now used world-wide to measure hearing as they are easy to make in any local language, to explain to participants and to do, and moreover can be done over the internet or telephone as they measure a relative threshold (signal-to-noise ratio), not an absolute threshold in dB SPL. Listeners are encouraged to set a volume that is comfortable and that does not distort or crackle, but is not too quiet.
This paper is a recent scoping review of the field. The particular version we used is Vlaming et al's high-frequency DTT, which uses a high-pass noise as the masker. Ours starts at -14 dB SNR, goes up/down at 2 dB steps per trial, and continues for 40 trials.
In the datafile, an average of the SNR for the last 30 trials is provided (labelled 'threshold'). For reference, the SNRs are supplied for each trial as well. The very first trial is practice and is not scored.
D Data file formats and naming conventions
D.1 Abbreviations in Filenames
R– “room”: e.g., “R02678” # Room ID linking to RAVEN rpf fileS– “scene”: e.g., S00121 # Scene ID for a particular setup in a room I.e., room + choice of target and interferer signalsBNC– BNC sentence identifier e.g. BNC_A06_01702CH–CH0– eardrum signalCH1– front signal, hearing aid channelCH2– middle signal, hearing aid channelCH3– rear signal, hearing aid channel
I/i1– Interferer, i.e., noise or sentence ID for the interferer/maskerT– talker who produced the target speech sentencesL– listenerE– entrant (identifying a team participating in the challenge)t– target (used in BRIRs and RAVEN project ‘rpf’ files)
D.2 General
- Audio and BRIRs will be 44.1 kHz 32 bit wav files in either mono or stereo as appropriate.
- Where stereo signals are provided, the two channels represent the left and right signals of the ear or hearing aid microphones.
- HRIRs have a sampling rate of 48 kHz.
- Metadata will be stored in JSON format wherever possible.
- Room descriptions are stored as RAVEN project ‘rpf’ configuration files.
- Signals are saved within the Python code as 32-bit floating point by default.
D.3 Prompt and transcription data
The following text is available for the target speech:
- Prompts are the text that was supposed to be spoken as presented to the readers.
- ‘Dot’ transcriptions contain the text as it was spoken in a form more suitable for scoring tools.
- These are stored in the master json metadata file.
D.4 Timing in audio files
- The target sound starts 2 seconds after the start of the interferer. This is so the target is clear and unambiguously identifiable for listening tests. This also gives the hearing aid algorithms some time to adjust to the background noise.
- The interferer continues 1 second after the target has finished, so that all words in the target utterance can be masked.
D.5 Source audio files
- Wav files containing the original source materials.
- Could be used as the clean speech reference in an intrusive (double-ended) prediction model
- Original target sentence recordings:
<Talker ID>_<BNC sentence identifier>.wav
D.6 Preprocessed scene signals
- Audio files storing the signals picked up by the hearing aid microphone ready for processing.
- Target_anechoic could be used as the clean speech reference in an intrusive (double-ended) prediction model.
- Separate signals are generated for each hearing aid microphone pair or ‘channel’.
<Scene ID>_target_<Channel ID>.wav
<Scene ID>_interferer_<Channel ID>.wav
<Scene ID>_mixed_<Channel ID>.wav
<Scene ID>_target_anechoic.wav
Scene ID – S00001 to S10000
Sfollowed by 5 digit integer with 0 pre-padding
Channel ID
CH0– Eardrum signalCH1– Hearing aid front microphoneCH2– Hearing aid middle microphoneCH3– Hearing aid rear microphone
D.7 Enhanced signals
These are the audio signals that the listeners heard during the speech intelligibility testing. The signals that are output by a given enhancement (hearing aid) model or system.
<Entrant ID>_<Scene ID>_<Listener ID>_HA-output.wav# HA output signal (i.e., as submitted by the challenge entrants)
Listener ID – ID of the listener panel member, e.g., L200 to L244.
D.8 Scene metadata
A JSON file called scenes.CPC1_train.json containing a description of each scene that is used in the listening experiments. It is a hierarchical dictionary, with the top level being scenes indexed by unique scene ID, and each scene described by a second-level dictionary. Here, viewvector indicates the direction vector or line of sight.
[
{
"scene": "S00001",
"room": {
"name": "R00001",
"dimensions": "5.9x3.4186x2.9" // Room dimensions in metres
},
"SNR": 3.8356,
"hrirfilename": "VP_N5-ED", // HRIR filename
"target": { // target positions (x,y,z) and view vectors (look directions, x,y,z)
"Positions": [
-0.5,
3.4,
1.2
],
"ViewVectors": [
0.291,
-0.957,
0
],
"name": "T022_HCS_00002", // target speaker code and BNCid
"nsamples": 153468, // length of target speech in samples
},
"listener": {
"Positions": [
0.2,
1.1,
1.2
],
"ViewVectors": [
-0.414,
0.91,
0
]
},
"interferer": {
"Positions": [
0.4,
3.2,
1.2
],
"name": "CIN_dishwasher_012", // interferer name
"nsamples": 1190700, // interferer length in samples
"duration": 27, // interferer duration in seconds
"type": "noise", // interferer type: noise or speech
"offset": 182115, // interferer segment starts at n samples from beginning of recording
},
"azimuth_target_listener": -7.55, // angle azimuth in degrees of target for receiver
"azimuth_interferer_listener": -29.92, // angle azimuth in degrees of interferer for receiver
"dataset": "train", // dataset: train, dev or eval/test
"pre_samples": 88200, // number of samples of interferer before target onset
"post_samples": 44100 // number of samples of interferer after target offset
},
{
// ... etc.
}
]
- There are JSON files containing the scene specifications per dataset, e.g., scenes.train.json.
- Note that the scene ID and room ID might have a one-to-one mapping in the challenge, but are not necessarily the same.
- A scene is completely described by the room ID and target and interferer source IDs, as all other information, e.g., source + target geometry are already in the RAVEN project rpf files. Only the room ID is needed to identify the BRIR files.
- The listener ID is not stored in the scene metadata; this information is stored separately in a
scenes_listeners.jsonfile. - Non-speech interferers are labelled
CIN_<noise type>_XXX, while speech interferers are labelled<three letter code including dialect and talker gender>_XXXXX.
D.9 Listener metadata
Listener audiogram data stored in a single JSON file called listeners.CPC1_train.json with the following format.
{
"L0001": {
"name": "L0001",
"audiogram_cfs": [250, 500, 1000, 2000, 3000, 4000, 6000, 8000],
"audiogram_levels_l": [10, 10, 20, 30, 40, 55, 55, 60],
"audiogram_levels_r": [10, 15, 25, 40, 50, 65, 65, 70 ],
},
"L0002": {
// ... etc.
},
// ... etc.
}
A spreadsheet named listener_data.CPC1_train.xlsx containing the SSQ12, GHAPB, DTT data for each listener where it is available.
D.10 Listener intelligibility data
JSON files CPC1.train.json (for Track 1) and CPC1.train_indep.json (for Track 2) which provides the responses made by the listeners when presented with a particular scene processed by a particular system. The data is a simple list of dictionaries with one entry for each listener response
[
{
"scene":"S08510", // The identity of the scene
"listener":"L0239", // The identity of the listener
"system":"E001", // The identify of the HA system
"prompt":"i suppose you wouldn't be free for dinner this evening", // The target sentence (prompt)
"response":"freeze evening", // The listeners response (transcript)
"n_words":10, // Number of words in the target sentence
"hits":1, // Number of words recognised correctly
"correctness":10.0, // The percentage of words recognised correctly
"signal":"S08510_L0239_E001" // The name of the file containing the signal listened to.
},
{
// ... etc.
},
// ... etc.
]
E. Reproduction Levels
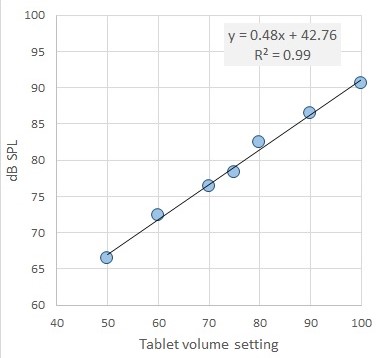
The graph gives the SPL from one of our headsets based on the volume level of the tablet. The input signal was ICRA speech-shaped noise [1], unmodulated in time, and scaled to an RMS of 0.3.
References
[1] ICRA standard noises, https://icra-audiology.org/Repository/icra-noise. We used track #1.