Scene Generation
Figure 1 shows the pipeline that generates the scenes.
- The ambisonics RIRs (Room Impulse Response) are generated through the geometric room acoustic model RAVEN [1] - blue box to left.
- The Scene Generator (middle blue box) works on the metadata (shown in green) to create the scene definition metadata, this includes:
- The metadata associated with the randomly generated scenarios in RPF and JSON format (described on the data page).
- The metadata for the target speech and the three types of noise interferer.
- The Scene Renderer takes the metadata, the ambisonics room impulse responses, and the audio of the target speech and interferers, and then produces:
- Ambisonic audio of the scene.
- Binaural audio for the hearing aid microphones.
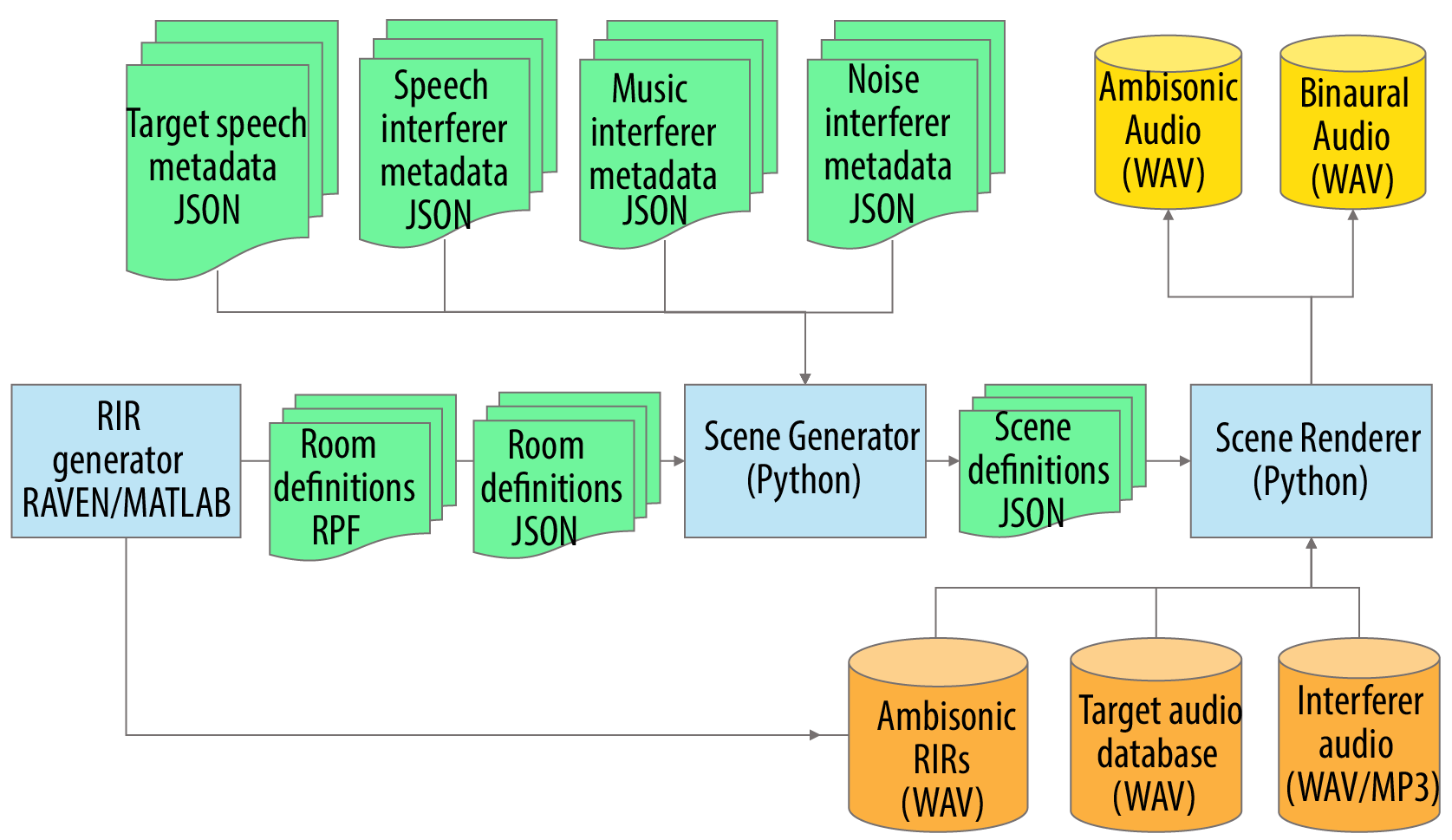
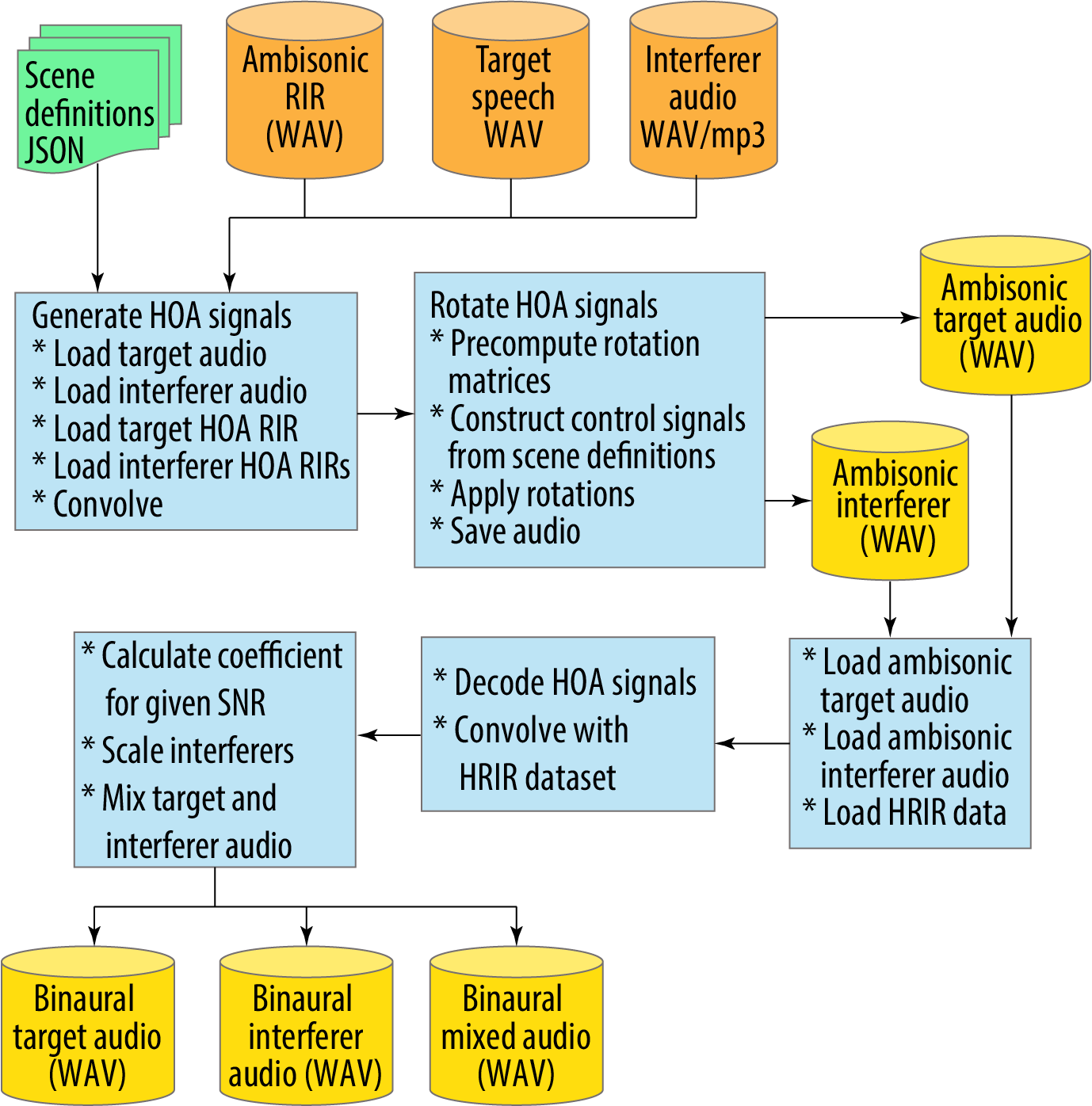
Figure 2 shows the scene renderer processing in detail:
- It takes the ambisonics room impulse responses (RIR); the target and interferer audio; and the scene definition metadata as the input (top line).
- First, it generates the HOA (High Order Ambisonic) signals through convolution (left blue box).
- Next, it applies the head rotations by rotating the HOA signals and creates ambisonic audio for both the target and interferer audio.
- The third row of three blue boxes is the process to take the ambisonic signals, apply the Head Related Room Impulse Responses (HRIR) to create the binaural signals at the hearing aid microphones (bottom line).
References
- Schröder, D. and Vorländer, M., 2011, January. RAVEN: A real-time framework for the auralization of interactive virtual environments. In Proceedings of Forum Acusticum 2011 (pp. 1541-1546). Denmark: Aalborg.