CEC1 Data
To obtain the data and baseline code, please see the download page.
A. Training, development, evaluation data
The dataset is split into these three subsets: training (train), development (dev) and evaluation (eval).
- You should only train on the training set.
- The system submitted should be chosen on the evidence provided by the development set.
- The final listening and ranking will be performed with the (held-out) evaluation set.
- For more information on supplementing the training data, please see the rules. The evaluation dataset will be made available one month before the challenge submission deadline.
B. The scene dataset
The complete dataset is composed of 10,000 scenes split into the following sets:
- Training (6000 scenes, 24 speakers);
- Development (2500 scenes, 10 speakers);
- Evaluation (1500 scenes, 6 speakers).
Each scene corresponds to a unique target utterance and a unique segment of noise from an interferer. The training, development and evaluation sets are disjoint for target speaker. The three sets are balanced for target speaker gender.
Binaural Room Impulse Responses (BRIRs) are used to model how the sound is altered as it propagates through the room and interacts with the head. The audio signals for the scenes are generated by convolving source signals with the BRIRs and summing. See the page on modelling the scenario for more details. Randomised room dimensions, target and interferer locations are used.
The BRIRs are generated for:
- A hearing aid with 3 microphone inputs (front, mid, rear). The hearing aid has a Behind-The-Ear (BTE) form factor; see Figure 1. The distance between microphones is approx. 7.6 mm. The properties of the tube and ear mould are not considered.
- Close to the eardrum.
- The anechoic target reference (front microphone).
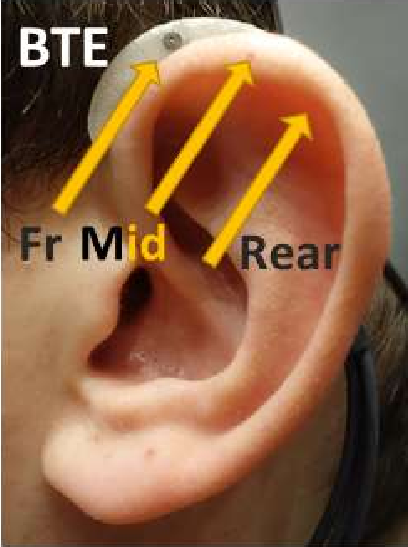
Figure 1. Front (Fr), Middle (Mid) and Rear microphones on a BTE hearing aid form.
Head Related Impulse Responses (HRIRs) are used to model how sound is altered as it propagates in a free-field and interacts with the head (i.e., no room is included). These are taken from the OlHeadHRTF database with permission. These include HRIRs for human heads and for three types of head-and-torso simulator/mannekin. The eardrum HRIRs (labelled ED) are for a position close to the eardrum of the open ear.
rpf files are specification files for the geometric room acoustic model that include a complete description of the room.
B.1 Training data
For each scene in the training data the following signals and metadata are available:
- The target and interferer BRIRs (4 pairs: front, mid, rear and eardrum for left and right ears).
- HRIRs including those corresponding to the target azimuth.
- The mono target and interferer signals (pre-convolution).
- For each hearing aid microphone (channels 1-3 where channel 1 is front, channel 2 is mid and channel 3 is rear) and a position close to the eardrum (channel 0):
- The target convolved with the appropriate BRIR;
- The interferer convolved with the appropriate BRIR;
- The sum of the target and interferer convolved.
- The target convolved with the anechoic BRIR (channel 1) for each ear (‘target_anechoic’).
- Metadata describing the scene: a JSON file containing, e.g., the filenames of the sources, the location of the sources, the viewvector of the target source, the location and viewvector of the receiver, the room dimensions (see specification below), and the room number, which corresponds to the RAVEN BRIR, rpf and ac files.
Software for generating more training data is also available.
B.2 Development data
The same data as for the training will be made available to allow you to fully examine the performance of your system. Note, that the data available for the evaluation will be much more limited (see B.3).
For each scene, during development, your hearing aid enhancement model must only use the following input signals/data:
- The sum of the target and interferer – mixed at the SNR specified in the scene metadata – at one or more hearing aid microphones (CH1, CH2 and/or CH3).
- The IDs of the listeners assigned to the scene in the metadata provided.
- The audiograms of these listeners.
B.3 Evaluation scene data
For each scene in the evaluation data only the following will be available:
- The sum of the target and interferer for each hearing aid microphone.
- The ID of the evaluation panel members/listeners who will be listening to the processed scene.
- The audiograms of these listeners.
C Listener data
C.1 Training and development data
A sample of pure tone air-conduction audiograms that characterise the hearing impairment of potential listeners, split into training and development sets.
C.2 Evaluation data
You will be given the left and right pure tone air-conduction audiograms for the listening panel, so the signals you generate for evaluation can be individualised to the listeners.
A panel of 50 hearing-aided listeners will be recruited for the evaluation panel. We plan that they will be experienced bilateral hearing-aid users (they use two hearing aids but the hearing loss may be asymmetrical) with an averaged hearing loss as measured by pure tone air-conduction of between 25 and about 60 dB in the better ear, with fluent speaking of (and listening to) British English.
D Data file formats and naming conventions
D.1 Abbreviations in Filenames
R– “room”: e.g., “R02678” # Room ID linking to RAVEN rpf fileS– “scene”: e.g., S00121 # Scene ID for a particular setup in a room I.e., room + choice of target and interferer signalsBNC– BNC sentence identifier e.g. BNC_A06_01702CH–CH0– eardrum signalCH1– front signal, hearing aid channelCH2– middle signal, hearing aid channelCH3– rear signal, hearing aid channel
I/i1– Interferer, i.e., noise or sentence ID for the interferer/maskerT– talker who produced the target speech sentencesL– listenerE– entrant (identifying a team participating in the challenge)t– target (used in BRIRs and RAVEN project ‘rpf’ files)
D.2 General
- Audio and BRIRs will be 44.1 kHz 32 bit wav files in either mono or stereo as appropriate.
- Where stereo signals are provided the two channels represent the left and right signals of the ear or hearing aid microphones.
- HRIRs have a sampling rate of 48 kHz.
- Metadata will be stored in JSON format wherever possible.
- Room descriptions are stored as RAVEN project ‘rpf’ configuration files.
- Signals are saved within the Python code as 32-bit floating point by default.
D.3 Prompt and transcription data
The following text is available for the target speech:
- Prompts are the text that was supposed to be spoken as presented to the readers.
- ‘Dot’ transcriptions contain the text as it was spoken in a form more suitable for scoring tools.
- These are stored in the master json metadata file.
D.4 Source audio files
- Wav files containing the original source materials.
- Original target sentence recordings:
<Talker ID>_<BNC sentence identifier>.wav
D.5 Preprocessed scene signals
Audio files storing the signals picked up by the hearing aid microphone ready for processing. Separate signals are generated for each hearing aid microphone pair or ‘channel’.
<Scene ID>_target_<Channel ID>.wav
<Scene ID>_interferer_<Channel ID>.wav
<Scene ID>_mixed_<Channel ID>.wav
<Scene ID>_target_anechoic.wav
Scene ID – S00001 to S10000
Sfollowed by 5 digit integer with 0 pre-padding
Channel ID
CH0– Eardrum signalCH1– Hearing aid front microphoneCH2– Hearing aid middle microphoneCH3– Hearing aid rear microphone
D.6 Enhanced signals
The signals that are output by the enhancement (hearing aid) model.
<Scene ID>_<Listener ID>_HA-output.wav#HA output signal (i.e., as submitted by the challenge entrants)
Listener ID – ID of the listener panel member, e.g., L001 to L100 for initial ‘pseudo-listeners’, etc. We are no longer providing the script for post-processing signals in preparation for the listener panel.
D.7 Enhanced signals processed by the hearing loss model
The signals that are produced by the hearing loss (HL) model.
<Scene ID>_<Listener ID>_HL-output.wavHL output signal<Scene ID>_<Listener ID>_HL-mixoutput.wavHL-processed CH0 signal, bypassing HA processing, for comparison<Scene ID>_<Listener ID>_flat0dB_HL-outputHL-output for flat 0 dB audiogram processed signal for comparison<Scene ID>_<Listener ID>_HLddf-outputunit impulse signal output by HL model for time-alignment of signals before processing by the baseline speech intelligibility model
D.8 Scene metadata
JSON file containing a description of the scene and assigns the scene to a specific member of the listening panel. It is a hierarchical dictionary, with the top level being scenes indexed by unique scene ID, and each scene described by a second-level dictionary. Here, viewvector indicates the direction vector or line of sight.
[
{
"scene": "S00001",
"room": {
"name": "R00001",
"dimensions": "5.9x3.4186x2.9" // Room dimensions in metres
},
"SNR": 3.8356,
"hrirfilename": "VP_N5-ED", // HRIR filename
"target": { // target positions (x,y,z) and view vectors (look directions, x,y,z)
"Positions": [
-0.5,
3.4,
1.2
],
"ViewVectors": [
0.291,
-0.957,
0
],
"name": "T022_HCS_00002", // target speaker code and BNCid
"nsamples": 153468, // length of target speech in samples
},
"listener": {
"Positions": [
0.2,
1.1,
1.2
],
"ViewVectors": [
-0.414,
0.91,
0
]
},
"interferer": {
"Positions": [
0.4,
3.2,
1.2
],
"name": "CIN_dishwasher_012", // interferer name
"nsamples": 1190700, // interferer length in samples
"duration": 27, // interferer duration in seconds
"type": "noise", // interferer type: noise or speech
"offset": 182115, // interferer segment starts at n samples from beginning of recording
},
"azimuth_target_listener": -7.55, // angle azimuth in degrees of target for receiver
"azimuth_interferer_listener": -29.92, // angle azimuth in degrees of interferer for receiver
"dataset": "train", // dataset: train, dev or eval/test
"pre_samples": 88200, // number of samples of interferer before target onset
"post_samples": 44100 // number of samples of interferer after target offset
},
{
// etc.
}
]
- There are JSON files containing the scene specifications per dataset, e.g., scenes.train.json.- Note, that the scene ID and room ID might have a one-to-one mapping in the challenge, but are not necessarily the same. Multiple scenes can be made by changing the target and masker choices for a given room. E.g., participants wanting to expand the training data could remix multiple scenes from the same room.
- A scene is completely described by the room ID and target and interferer source IDs, as all other information, e.g., source + target geometry are already in the RAVEN project rpf files. Only the room ID is needed to identify the BRIR files.
- The listener ID is not stored in the scene metadata; this information is stored separately in a
scenes_listeners.jsonfile. - Non-speech interferers are labelled
CIN_<noise type>_XXX, while speech interferers are labelled<three letter code including dialect and talker gender>_XXXXX.
D.9 Listener metadata
Listener data stored in a single JSON file with the following format.
{
"L0001": {
"name": "L0001",
"audiogram_cfs": [250, 500, 1000, 2000, 3000, 4000, 6000, 8000],
"audiogram_levels_l": [10, 10, 20, 30, 40, 55, 55, 60],
"audiogram_levels_r": [ 10, 15, 25, 40, 50, 65, 65, 70 ],
},
"L0002": {
// ... etc
},
// ... etc
}
D.10 Scene-Listener map
JSON file named scenes_listeners.json dictates which scenes are to be processed by which listeners.
{
"S00001": ["L0001", "L0002", "L0003"],
"S00002": ["L0003". "L0005", "L0007"],
// etc
}