Why use machine learning challenges for hearing aids?

The Clarity Project is based around the idea that machine learning challenges could improve hearing aid signal processing. After all this has happened in other areas, such as automatic speech recognition (ASR) in the presence of noise. The improvements in ASR have happened because of:
- Machine learning (ML) at scale – big data and raw GPU power.
- Benchmarking – research has developed around community-organised evaluations or challenges.
- Collaboration has been enabled by these challenges, allowing working across communities such as signal processing, acoustic modelling, language modelling and machine learning
We’re hoping that these three mechanisms can drive improvements in hearing aids.
Components of a challenge
There needs to be a common task based on a target application scenario to allow communities to gain from benchmarking and collaboration. Clarity project’s first enhancement challenge will be about hearing speech from a single talker in a typical living room, where there is one source of noise and a little reverberation.
We’re currently working on developing simulation tools to allow us to generate our living room data. The room acoustic will be simulated using RAVEN and the Hearing Device Head-related Transfer Functions will come from Denk’s work. We’re working on getting better, more ecologically valid speech than is often used in speech intelligibility work.
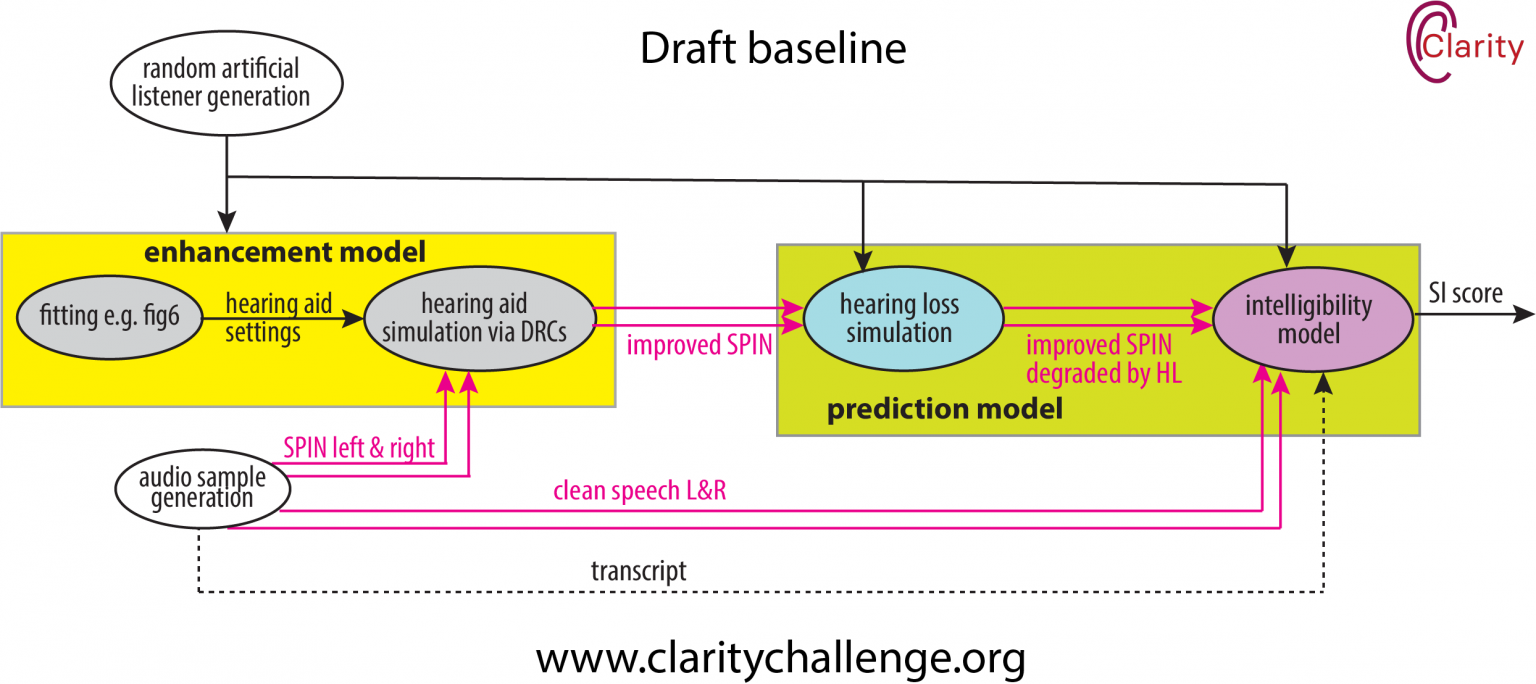
Entrants are then given training data and development (dev) test data along with a baseline system that represents the current state-of-the-art. You can find a post and video on the current thinking on the baseline here. We’re still working on the rules stipulating what is and what is not allowed (for example, will entrants be allowed to use data from outside the challenge).
Clarity’s first enhancement challenge is focussed on maximising the speech intelligibility (SI) score. We will evaluate this first through a prediciton model that is based on a hearing loss simulation and an objective metric for speech intellibility. Simulation has been hugely important for generating training data in the CHIME challenges and so we intend to use that approach in Clarity. But results from simulated test sets cannot be trusted and hence a second evaluation will come through perceptual tests on hearing impaired subjects. However, one of our current problems is that we can’t bring listeners into our labs because of COVID-19.
We’ll actually be running two challenges in roughly parallel, because we’re also going to task the community to improve our prediction model for speech intelligibility.
We’re running a series of challenges over five years. What other scenarios should we consider? What speech? What noise? What environment? Please comment below.
Acknowledgements
Much of this text is based on Jon Barker’s 2020 SPIN keynote