Overview
This page details the scenario that we have simulated to create the speech-in-noise samples, which were processed by the (simulated) hearing aids. The processed signals were played to listeners in listening tests to obtain the measured speech intelligibility scores.
It is perfectly possible to compete in the prediction challenge without knowing the information provided on this page, it provides context.
You could just work with the processed signals from the hearing aids and the listening test scores. However, some will find this information useful, for example, because it might inform the sourcing or creation of additional data, for example to be used for unsupervised pre-training.
Simulating the audio signals that were processed by the hearing aids
A listener (or receiver) is in a small room that has low to moderate reverberation. They are listening to a target talker, who is selected from our set of 40 speakers. The target talker is producing one of our unique 7-10 word Clarity sentences. Simultaneously, an interferer sound is playing. This is either a competing talker or a continuous noise source (e.g., a washing machine). The target and interferer are at the same height as the listener. The room dimensions, boundary materials, and the locations of the listener, target and interferer are randomised (discussed below). An example scenario is shown in Figure 1. The room geometry showing origin location is defined in Figure 2.
- Example Overview
- Geometry Definition
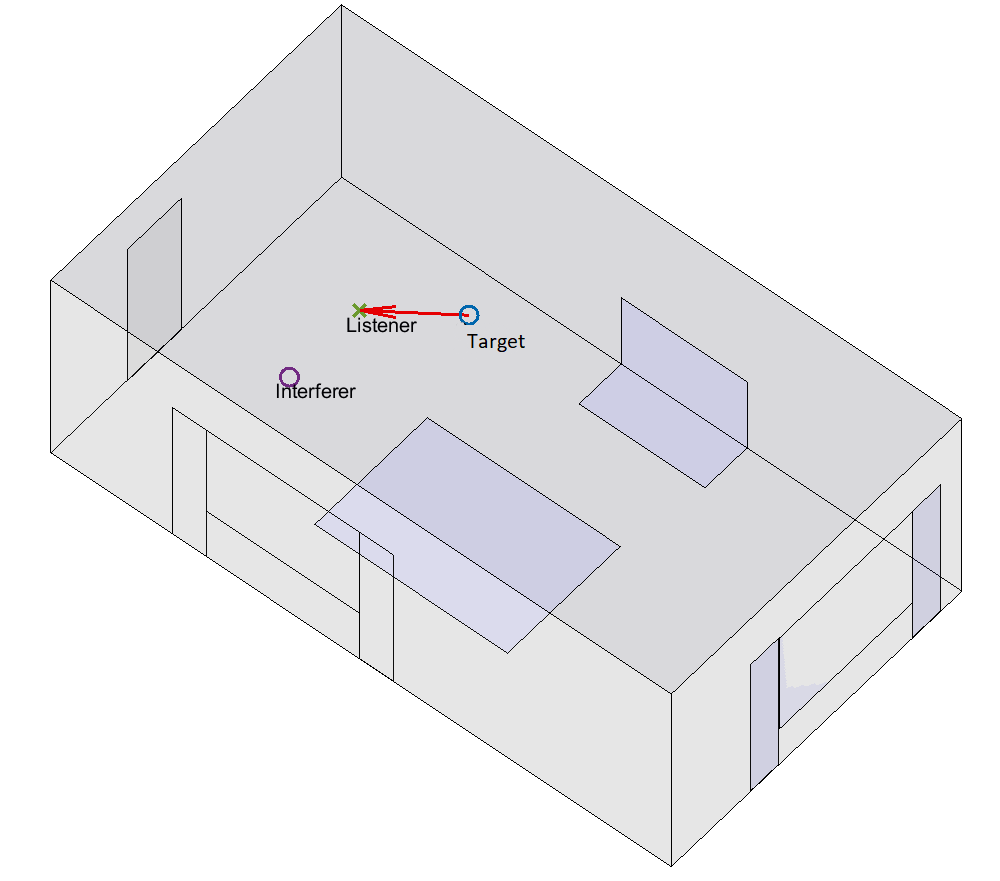
Figure 1. Example overview
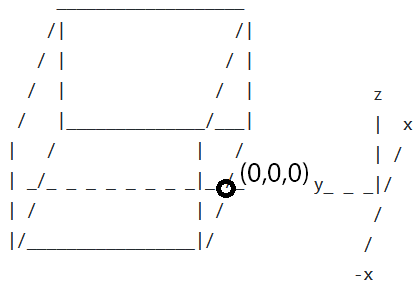
Figure 2. Geometry definition
Figure 3, below, shows the basic scene generator. The sound at the receiver is generated first by convolving the source signals with Binaural Room Impulse Responses (BRIRs). This generates reverberated speech and noise that includes the effects of the room and reflections from the listener's head. The reverberated speech and noise signals are then summed after appropriate gains are applied. The gains are set to achieve a Signal-to-Noise Ratio (SNR), which is chosen randomly between limits. The BRIRs are generated using the RAVEN Geometric Room Acoustic Model [1].
There are additional signal paths and outputs generated that have been omitted from Figure 3 for clarity. In addition to the reverberated signals associated with the hearing aid microphones, the signal close to the eardrum is also generated. You can also access the reverberated speech and noise signals before they are mixed.
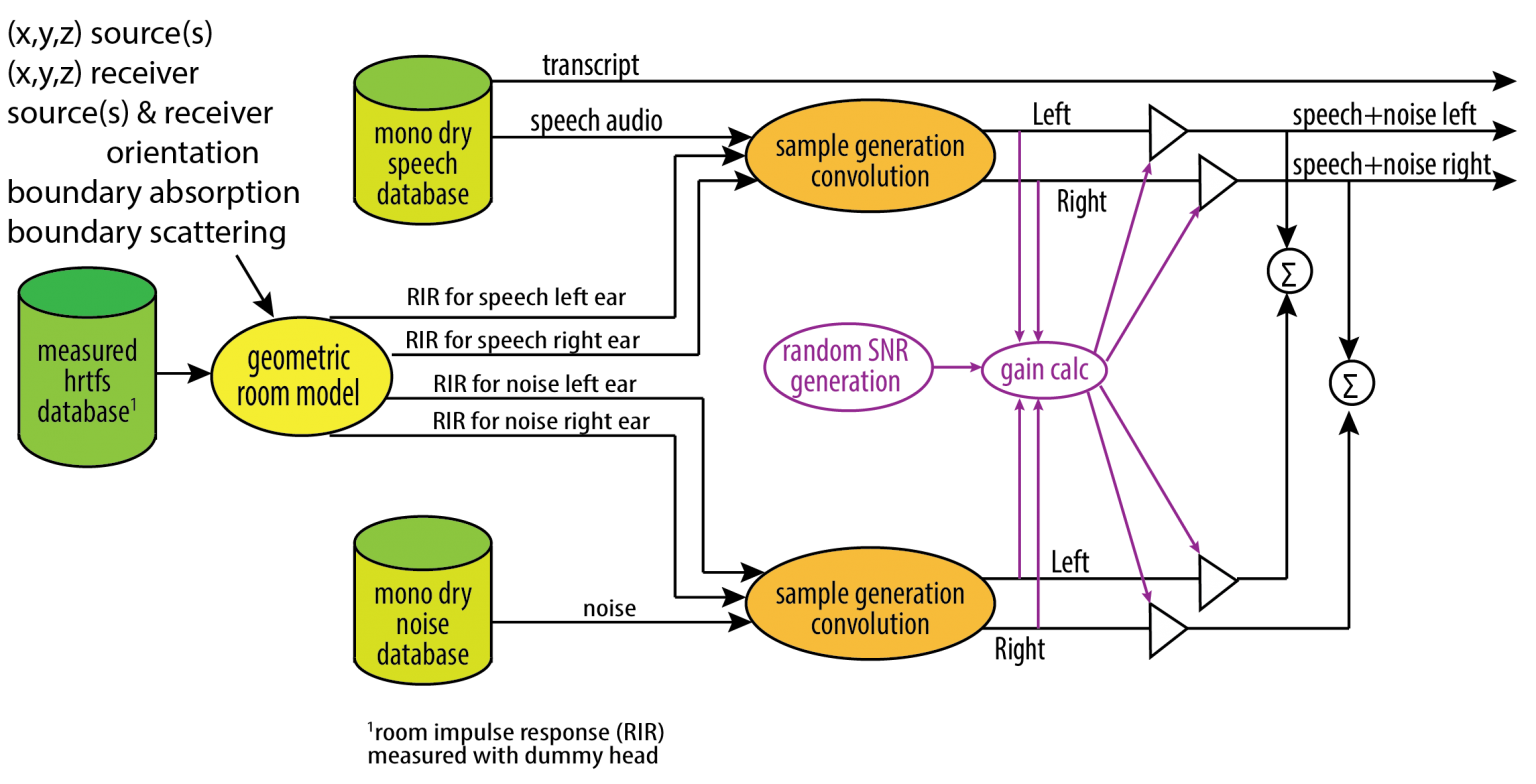
Figure 3. Simplified diagram of the scene generator. RIR refers to Room Impulse Response, HRTFs refers to Head Related Transfer Functions, SNRs are signal-to-noise ratios, and gain calc. indicates gain calculation. Dry here means anechoic. The outputs are noisy speech signals.
Room Geometry
- Cuboid rooms with dimensions length, , by width, , by height, .
- Length set using a uniform probability distribution random number generator with .
- Height set using a Gaussian distribution random number generator with a mean of and standard deviation of .
- Area set using a Gaussian distribution random number generator with mean and standard deviation of .
Room Materials
One of the walls of the room is randomly selected for the location of the door. The door can be at any position with the constraint of being at least at 20 cm from the corner of the wall.
A window is placed on one of the other three walls. The window could be at any position of the wall but at 1.9 m height and at 0.4 m from any corner. The curtains are simulated to the side of the window. For larger rooms, a second window and curtains are simulated following a similar methodology.
A sofa is simulated at a random position as a layer on the wall and the floor. Finally, a rug is simulated at a random location on the floor.
The receiver
The receiver has position,
This is positioned within the room using uniform probability distribution random number generators for the x and y coordinates (see Figure 2 for origin location). The reciver can have one of two heights (seated or standing height). There are constraints to ensure that the receiver is not too close to the wall:
- either (sitting) or (standing).
The receiver is positioned so as to be roughly facing the target talker. That is to say, within degrees of target. The angle = where is an integer and .
The target talker
The target talker has position
The target talker is positioned within the room using uniform probability distribution random number generators for the coordinates. Constraints ensure the target is not too close to the wall or receiver. It is set to have the same height as the receiver.
A speech directivity pattern is used, which is directed at the listener.
The interferer
The interferer has position
The interferer is a single point source radiating speech or non-speech noise omnidirectionally. It is placed within the room using uniform probability distribution random number generators for the coordinates. These constraints ensure the interferer is not too close to the wall or receiver. It is set to be at the same height as the receiver. Note, this means that the interferer can be at any angle relative to the receiver.
Timing
- The target sound starts 2 seconds after the start of the interferer. This is so the target is clear and unambiguously identifiable for listening tests. This also gives the hearing aid algorithms some time to adjust to the background noise.
- The interferer continues 1 second after the target has finished, so that all words in the target utterance can be masked.
Signal-to-Noise Ratio (SNR)
The mixtures are engineered such that the target utterances are at an appropriate level of intelligibility when processed by the default hearing aid software. This is achieved by scaling the interferer. Pilot tests have been conducted to get this approximately correct. Scaling is done this way because it does not require recomputing the BRIRs. Note that the interferer can be at any azimuth from the point of view of the listener/receiver.
A desired signal-to-noise ratio, SNRD (dB), is chosen using a uniform probability distribution random number generator between the limits of ranges specified for the speech and non-speech interferers. The calculation is based on the ear that has the better signal to noise ratio, as this mimics the better ear effect in binaural listening, where listeners focus on the ear that has the best SNR. The better ear SNR (BE_SNR) is calculated for the reference channel (channel 1, which corresponds to the front microphone of the hearing aid). This value is used to scale all interferer channels. The procedure is described below.
For the reference channel,
- The segment of the interferer that overlaps with the target (without padding) , i‘, and the target (without padding), t‘, are extracted
- Speech-weighted SNRs are calculated for each ear, SNRL and SNRR:
- Signals i‘ and t’ are separately convolved with a speech-weighting filter, h (specified below).
- The rms is calculated for each convolved signal.
- SNRL and SNRR are calculated as the ratio of these rms values.
- The BE_SNR is selected as the maximum of the two SNRs: BE_SNR = max(SNRL and SNRR).
Then per channel,
- The whole interferer signal, i, is scaled by the BE_SNR
- Finally, i is scaled as follows:
The speech-weighting filter is an FIR designed using the host window method [2, 3]. The specification is:
- Frequency (Hz) =
[0, 150, 250, 350, 450, 4000, 4800, 5800, 7000, 8500, 9500, 22050]; - Magnitude of transfer function at each frequency =
[0.0001, 0.0103, 0.0261, 0.0419, 0.0577, 0.0577, 0.046, 0.0343, 0.0226, 0.0110, 0.0001, 0.0001];
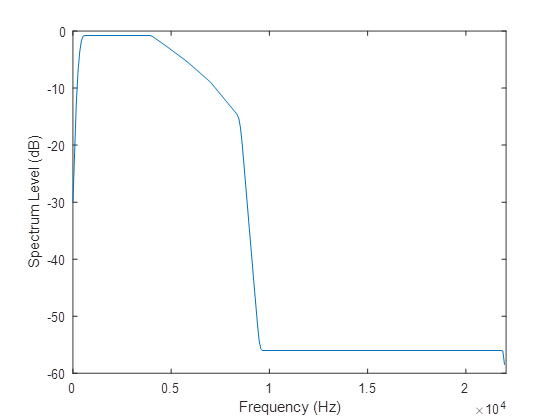
Figure 4, Speech weighting filter transfer function graph.
References
- Schröder, D. and Vorländer, M., 2011, January. RAVEN: A real-time framework for the auralization of interactive virtual environments. In Proceedings of Forum Acusticum 2011 (pp. 1541-1546). Denmark: Aalborg.
- Abed, A.H.M. and Cain, G.D., 1978. Low-pass digital filtering with the host windowing design technique. Radio and Electronic Engineer, 48(6), pp.293-300.
- Abed, A.E. and Cain, G., 1984. The host windowing technique for FIR digital filter design. IEEE transactions on acoustics, speech, and signal processing, 32(4), pp.683-694.